
核心论点
本视频的核心观点是,在使用神经网络(尤其是LSTM)进行金融时间序列(如股价)预测时,一个看似“完美”的预测结果往往具有高度的误导性。预测的真正价值不在于模型表面上的准确率,而在于是否定义了有实际意义的预测目标。
关键对比实验:两种不同的预测目标
视频通过对比两种不同的预测目标,清晰地揭示了这一陷阱。
方法一:预测“下一个收盘价”(The Misleading Approach | 错误的思路)
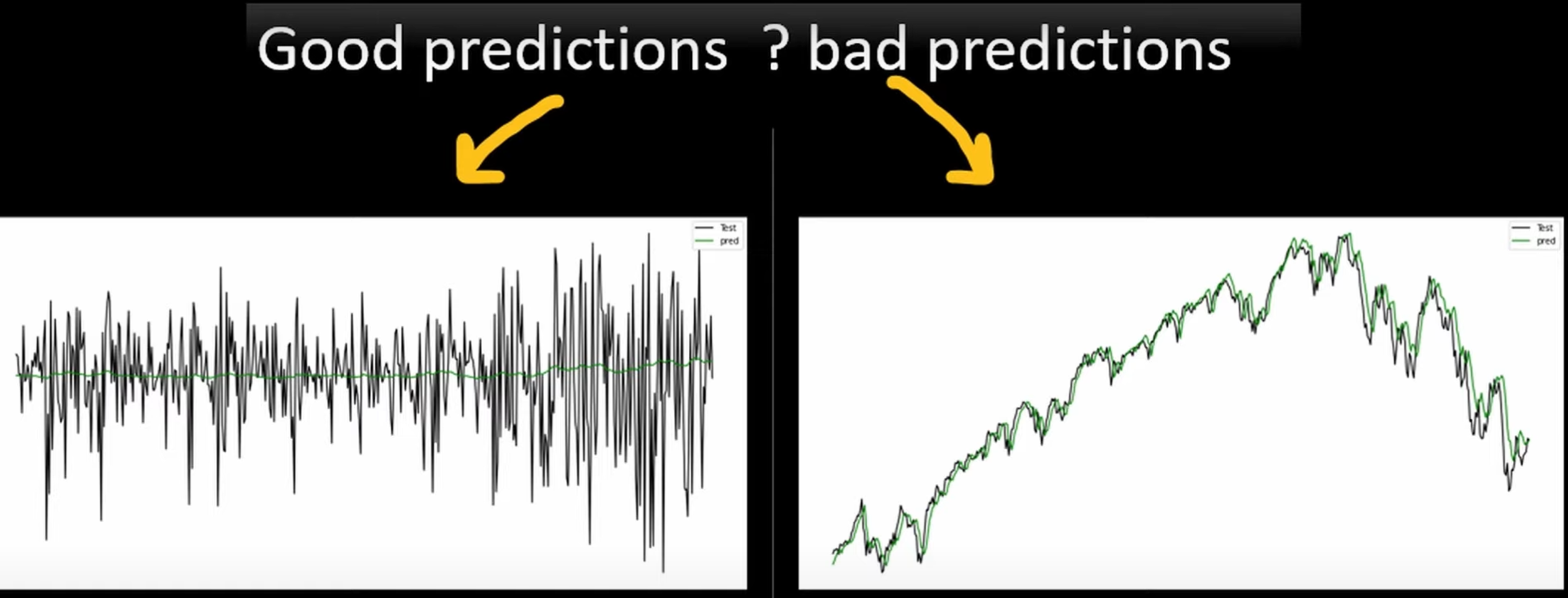
- 预测目标 (Target): 直接预测下一个时间单位(如下一根K线)的收盘价格。
- 实验结果 (Result):
- 在图表上,预测曲线与真实价格曲线几乎完美重合,误差极小。
- 给人一种模型已经成功掌握了价格变动规律的**“假象”**。
- 问题剖析 (Analysis of the Trap):
- 高自相关性:金融数据具有很强的时间连续性,即今天的收盘价与明天的收盘价本身就非常接近。
- 模型的“懒惰学习”:模型发现,要使损失函数最小化(即提高准确率),最简单的策略就是输出一个与当前输入价格非常接近的值。本质上,模型学到的是
预测价(t+1) ≈ 真实价(t)。 - 实际价值 = 零:这个看似准确的预测实际上只是真实价格的一个**“滞后镜像”,它无法提供任何关于未来价格会上涨还是下跌**的有效信息,因此对交易决策毫无帮助。
方法二:预测“价格的变动量”(The Meaningful Approach | 有意义的思路)
- 预测目标 (Target): 预测下一个时间单位价格的变化量(
下一收盘价 - 当前收盘价)。 - 实验结果 (Result):
- 预测曲线与真实的价格变动曲线差异巨大,效果非常不理想。
- 直观地展示了预测市场真实波动的极端困难性。
- 价值剖析 (Analysis of the Value):
- 正确的方向:尽管结果不佳,但这才是真正有价值的预测方向。准确预测价格的变动方向和幅度,才能产生可执行的交易信号。
- 反映真实难度:这个不理想的结果诚实地反映了使用单一模型预测市场走向的真实挑战。
模型与数据技术细节
- 所用模型:LSTM (Long Short-Term Memory | 长短期记忆网络),一种适用于处理时间序列数据的循环神经网络。
- 输入特征 (Input Features):
- 基础价格数据:开盘价 (Open), 最高价 (High), 最低价 (Low), 收盘价 (Close)。
- 技术指标:相对强弱指数 (RSI), 移动平均线 (Moving Averages) 等。
- 数据准备流程:
- 定义回溯期 (Look-back Period):决定用过去多少个时间单位的数据(如过去20-30天)来预测下一个时间单位。
- 数据划分:将总数据集的80%用作训练集,20%用作测试集。
- 数据缩放 (Scaling):在将数据送入神经网络前,通常需要进行归一化或标准化处理。
结论与未来改进方向
- 核心结论: 在进行金融预测建模时,必须对结果保持批判性思维。模型的设置,尤其是预测目标的选择,直接决定了其是否有用。一个丑陋但诚实的结果,远比一个漂亮但虚假的结果更有价值。
- 未来可行的改进方向:
- 特征工程 (Feature Engineering):探索和筛选对预测价格“变化”更有帮助的技术指标和数据。
- 优化预测目标 (Refining the Target):不直接预测精确的变化数值,可以简化问题,例如预测价格变化的**“方向”**(即涨、跌、平)。
- 超参数调优 (Hyperparameter Tuning):
- 寻找最佳的回溯期长度。
- 优化模型的网络结构,如层数、每层的神经元数量等。
在线演示
🚀 启动交互式演示