
比赛简介
「用户新增预测挑战赛」是由科大讯飞主办的一项数据科学竞赛,旨在通过机器学习方法预测用户是否为新增用户
比赛属于二分类任务,评价指标采用F1分数,分数越高表示模型性能越好。
如果你有一份带标签的表格型数据,只要目标是分类、回归或排序,那么 LightGBM 都是最强机器学习模型之一,默认首选。
赛题建模的价值
用户新增预测是分析 用户使用场景 以及 预测用户增长情况 的关键步骤,有助于进行其后续产品和应用的迭代升级,主要有对行业和技术有如下价值:
行业价值:
精准预测用户增长趋势,优化产品迭代方向
降低用户获取成本,提高营销转化率
为AI能力落地提供量化评估依据
技术价值:
解决实际业务场景中的用户增长预测问题
验证AI在用户行为分析领域的有效性
建立可复用的用户增长预测方法论
赛题要求:
参与算法赛事,一定要仔细理解赛事的 输入-输出 究竟是什么,尤其是提交的格式
输入数据:
用户行为事件记录
15个原始特征字段
关键字段:
udmap(JSON)、common_ts(时间戳)
输出要求:
预测用户是否为新增 (
is_new_did)提交格式:CSV文件包含一列,字段名为
is_new_did,值为0/10表示不是新增用户1表示是新增用户
原始数据初步预览
其中:
mid为用户行为模块id,eid为用户行为事件id,
解析一下两者的区别:
mid(模块ID):是一类行为的编号,表示用户在做什么“类型”的事情,比如:mid = 1:表示“浏览商品模块”
mid = 2:表示“搜索模块”
mid = 3:表示“结算模块”
所以它更像是一个大分类,告诉我们用户当前在哪个模块里操作。
eid(事件ID):是具体某个行为的编号,它属于某个模块(mid),但粒度更细,比如:在“浏览商品模块”中(mid=1),可能有:
eid = 101:点击商品详情
eid = 102:滑动商品列表
在“搜索模块”中(mid=2),可能有:
eid = 201:输入关键词
eid = 202:点击搜索按钮
did为用户id,device_brand为设备品牌/厂商,ntt为网络类型,operator为运营商,common_country为国家,common_province为省份,common_city为城市,appver为应用版本,channel为应用渠道,common_ts为事件发生时间(毫秒时间戳),os_type用于判断Android还是iOS,udmap为事件自定义属性(标准json文本,内含botId助手ID和pluginId插件ID)is_new_did为预测目标,即是否为新增用户
分析训练集与测试集用户重叠度
然后我们可以通过 经验/资料查阅肉眼观测/代码 等手段,对 赛事提供的数据 有大致的理解和把握:
提取了训练集和测试集中的所有唯一用户ID,分别组成集合
1 | train_dids = set(train_df['did'].unique()) |
计算两者交集
1 | overlap_dids = train_dids & test_dids |
统计数量
1 | num_overlap = len(overlap_dids) |
计算比例:
1 | ratio_in_train = num_overlap / num_train |
我们通过数据探索的代码,有一些关键发现:
测试集中93%的用户出现在训练集中
训练集中88%的用户
is_new_did为 0
建模初步思路
数据处理与特征工程: 如处理缺失值、异常值,解析JSON字段,从时间戳中提取特征(年、月、日、小时等),以及构造新的特征以提升模型表现。
分类模型与集成学习: 了解常用的分类算法(如逻辑回归、决策树、随机森林等),特别是梯度提升树(如LightGBM)的原理和使用。LightGBM是微软开发的高效梯度提升框架,具有训练速度快、内存占用低和精度高等优点。
模型评估与指标: 掌握二分类问题的评估指标,如精确率(Precision)、召回率(Recall)和F1分数的定义及计算方法。F1分数是精确率和召回率的调和均值,在正负样本不均衡时比准确率更有参考意义。
交叉验证: 理解交叉验证的作用,能够使用分层K折交叉验证来评估模型性能,避免因随机划分导致的偏差。
超参数调优: 熟悉如何调整模型的超参数(如学习率、树的深度等)以提高模型效果,常用方法包括网格搜索、随机搜索和贝叶斯优化等。
结果提交与分析: 了解竞赛提交的格式要求,能够将模型预测结果生成符合要求的CSV文件提交,并通过排行榜成绩分析模型改进方向。
解题 要点和难点
用户行为事件数据 → 用户级别预测
高维稀疏特征(设备/地域/行为ID)
像device_brand,common_city,mid,eid这类字段,有成百上千种取值。用 One-hot 编码会变成高维稀疏矩阵,容易导致模型训练慢、过拟合,必须小心处理,比如可以做频率编码、embedding、或仅保留Top-N正负样本不均衡(新增用户占比较少)
is_new_did的 0 和 1 不平衡,大多数是老用户(0)。这会让模型“只学会预测0”,所以需要:采样策略(欠采样、过采样)
- 比如统计:
- 用户一共触发了几个行为(行为数量)
- 用户用过哪些网络、在哪些城市
- 用户行为的时间分布(首次时间、活跃时段等)
这是建模效果优劣的关键步骤。
合理评价指标(如AUC或F1,而不是Accuracy)
使用内置样本权重的模型(如 LightGBM)
用户行为聚合:如何将事件级数据转化为用户特征
数据是以“行为事件”为单位的,比如用户点击了某个按钮,这样的行为记录很多,但我们的目标是预测“某个用户是否是新用户”,所以我们需要将多条事件数据合并成一个用户级别的数据,这是一个“从行到列”的特征聚合问题。时间敏感特征:用户行为模式随时间变化
比如一个用户一开始很频繁,后面沉寂,也许是老用户;新用户行为更集中在某几个小时;时间戳可以提取:- 小时、星期几、行为密度
- 首次行为和最后一次行为的间隔
- 是否在特定时间段活跃(如晚上活跃)
解题思考过程
关键决策点:
选择树模型而非神经网络(训练速度/特征处理)
优先构造简单的时间特征而非复杂特征工程
参考资料:
LightGBM官方文档(分类任务参数配置)
时序特征工程最佳实践(FeatureTools库)
Baseline方案的设计思路
核心函数1:交叉验证建模
1 | n_folds = 5 |
细节补充(什么是k-fold cross-validation):

根据题型还要有的改进点:
使用StratifiedKFold
如果你在处理的是分类问题,并且正负样本比例不平衡(比如“新增用户”只占很少),那你用的 StratifiedKFold 就更进一步了,它在划分每一份的时候,还会确保正负样本的比例一致,这能避免某一折验证集全是负样本,导致模型评估不准。
核心函数2:目标优化函数
1 | def find_optimal_threshold(y_true, y_pred_proba): |
背景:
在二分类模型中,很多模型(比如 LightGBM、XGBoost)输出的不是“0”或“1”的标签,而是一个概率(比如这个样本属于正类的概率是 0.73)
但我们最终要做出决策:到底是正类(1)还是负类(0)?这就需要设置一个“阈值”来做转换
例如:默认是用 0.5,当预测概率大于 0.5 就认为是正类。但这个阈值不是固定的,在样本不均衡或业务目标特殊时,调整阈值可以显著提升 F1 等指标。
设计特点:
- 候选范围选择
聚焦 0.1-0.4:适用于正例稀少的场景(如欺诈检测)
若正例比例高,可扩展范围至
np.arange(0.05, 0.95, 0.05)
- 数值稳定性
避免使用
np.ptp等可能受异常值影响的指标离散化搜索简单高效,复杂度 O(n)
合并数据做特征工程(补充)
1. 类别特征编码一致性
1 | for feature in cat_features: |
le.fit(values)这一步是“学习”阶段:它会扫描values中所有不同的取值,按字典序排序,然后给每个唯一类别分配一个整数标签(从 0 开始)。这些映射规则保存在le.classes_属性里。然后用
le.transform(...)把原始列中的每个值,根据这个映射规则变成整数(比如['banana', 'apple']→[1, 0])。最后,这些编码后的数字会“回填到数据集的原列里”,替换掉原来的字符串
关键问题:如果分别编码,可能出现:
- 训练集中
device_brand='Apple'编码为0 - 测试集中
device_brand='Apple'编码为1 - 导致模型无法正确识别相同的设备品牌
2. 统计特征的完整性
1 | # 基于合并数据计算统计特征 |
优势:
- 统计更准确(基于更大的样本)
- 避免训练集和测试集统计分布不一致
- 提高特征的泛化能力
3. 数据泄露检查
1 | # 注意:标签信息只在训练集中存在 |
安全性:
- 测试集中的
is_new_did列为NaN - 只使用特征信息,不使用标签信息
- 不会造成数据泄露
聚合的意义(补充)
原始数据的真实结构:
一行 ≠ 一个用户的所有行为
一行 = 一次用户行为事件,不是用户全部行为
从代码中可以看出:
- 训练集大小: (3,429,925, 15) - 343万条记录
- 唯一用户数: 270,837 个用户
- 这意味着:平均每个用户有 12.7 条记录
1 | # 证明:每个用户有多条记录 |
🔍 具体例子说明
原始数据长这样:
1 | did eid common_ts device_brand hour is_new_did |
问题是什么?
每一行只代表用户的一次行为事件,而不是用户的全部行为!
- 第0行:用户001在14:00触发了事件100
- 第1行:用户001在14:00触发了事件200
- 第2行:用户001在15:00触发了事件300
- 第3行:用户001在16:00又触发了事件100
我们需要用户级别的特征!
🎯 为什么要聚合?
1. 单行信息不足
- 单行只能告诉我们:这个用户在某个时间点做了什么
- 无法告诉我们:这个用户的整体行为模式
2. 用户级别特征更重要
1 | # 没有聚合的情况下,我们只知道: |
3. 模型需要用户画像
- 活跃用户: 高频次、多事件类型、最近活跃
- 不活跃用户: 低频次、单一事件、很久没活跃
💡 实际价值
聚合特征能回答的问题:
- 这个用户活跃吗? →
frequency(行为频次) - 这个用户最近活跃吗? →
recency(最近活跃时间) - 这个用户行为多样吗? →
monetary(不同事件类型数) - 这个用户是重度用户吗? → 综合RFM得分
这些特征对预测”新用户”很重要:
- 新用户: 通常频次低、事件类型少、最近注册
- 老用户: 通常频次高、事件类型多、历史悠久
🎯 总结
聚合的核心价值:
- 将用户的多次行为汇总成用户画像
- 从事件级别提升到用户级别的特征
- 为模型提供更丰富的用户行为信息
没有聚合:只知道用户做了什么
有了聚合:知道用户是什么样的人
Baseline方案的优缺点
方案优点:
数据预处理完整
时间特征提取:将毫秒时间戳转换为
day、dayofweek、hour等可解释的时序特征,捕捉用户行为的周期性规律。类别特征编码:对
device_brand、operator等高基数类别特征使用LabelEncoder进行编码,避免了独热编码导致的维度爆炸问题。交叉验证策略:采用
StratifiedKFold分层交叉验证,确保训练集和验证集的类别分布一致性,减少模型偏差。
模型选择合理
使用LightGBM作为基模型,适合高维稀疏数据,且对类别特征处理友好(如
udmap中的JSON字段)。阈值优化:通过动态调整分类阈值(
find_optimal_threshold)最大化F1分数,适应类别不平衡问题(新增用户比例较低)。
特征重要性分析
- 输出特征重要性(
gain),帮助识别关键特征(如udmap中的插件ID或助手ID),为后续特征优化提供方向。
- 输出特征重要性(
方案不足:
特征工程深度不足
未充分挖掘
udmap字段中的JSON信息(如botId、pluginId),仅将其作为类别特征处理,未提取组合特征(如botId+pluginId的交互)。忽略用户行为序列模式(如用户访问频次、事件路径),未能构建基于时间窗口的统计特征(如24小时内访问次数、连续登录天数)。
模型调参空间有限
参数固定(如
max_depth=12、num_leaves=63),未通过网格搜索或贝叶斯优化探索更优参数组合。未尝试集成模型(如CatBoost、XGBoost)或模型融合策略(如Stacking)提升泛化能力
进阶要点1:如何挖掘用户行为信息
时间序列特征:
- 滑动窗口统计:计算用户在最近7天、30天内的行为频次(如
eid事件发生次数)、活跃时长(连续登录天数)。 - 示例代码:
1 | # 按用户分组,按时间排序 |
RFM特征:
Recency(最近一次行为时间):计算用户最近一次行为距离当前时间的天数。
Frequency(行为频率):用户总行为次数。
Monetary(行为价值):假设某些事件(如
eid)有经济价值,可定义虚拟价值字段。示例代码:
1 | %%time |
聚类之前,我们通常需要构造用户画像,也就是将“用户在某一时刻做了一件事”这一行级别的记录,转化为用户级别的特征向量(也可以理解为把行为日志「压缩」成特征摘要),RFM 就是一种典型方式(Recency 最近行为时间、Frequency 总行为次数、Monetary 用户价值或活跃度等)。因为你的原始数据是按行为记录来组织的,每一行是某个用户某个时间的行为,所以我们必须在 full_df(通常是训练集和测试集拼接后)中 以用户ID为单位聚合,计算出这些用户级的特征。
这一步就是对每个用户的所有行为求统计量:比如用户最后一次行为距现在多长时间、行为次数是多少、涉及的内容有多少种、最早和最晚的时间戳等。这些值都是用户的静态画像特征,适合用于聚类或训练模型。
但问题来了:原始的 train_df 和 test_df 还是按行为来组织的,而我们刚刚生成的是每个用户一行的 rfm_agg。所以我们需要 把这些用户特征“广播”回去合并到每条行为记录中(也就是你看到的 merge 操作),使得后续训练模型时,每条行为记录都能携带所属用户的画像。
这一步很关键,它是“先聚合再拆开”的意思:先在完整数据集上聚合用户级特征,再分别合并到训练集和测试集中。这样做是因为:
RFM 特征是用户静态特征,不应该因训练/测试划分而不同;
若只用
train_df聚合,会导致测试集中部分用户特征缺失;若不合并,而是直接聚类用户,会失去原始行为粒度的信息,无法训练分类模型。
总结一句话就是:聚类或RFM特征是“以用户为单位的全局视角”,而行为数据是“以行为为单位的局部视角”。我们需要通过聚合(groupby)+ merge(合并)来建立两者之间的桥梁。这种设计让你既能提取用户画像,又能在每条行为记录中使用这些聚类信息做模型训练
组合特征与高阶交互
目标:通过特征交叉和非线性组合,捕捉复杂模式。
方法:
- 类别特征交叉:
- 将
device_brand与os_type组合(如Android_Samsung),反映设备-系统的用户偏好。 - 示例代码:
- 将
1 | train_df['device_os'] = train_df['device_brand'].astype(str) + '_' + train_df['os_type'].astype(str) |
- 数值特征分桶与交叉:
- 将将
common_ts分桶为时间段(如早高峰、晚高峰),与hour特征交叉,分析用户在特定时段的行为差异。 - 示例代码:
- 将将
1 | # 分桶:将时间戳转换为时间段(如0-6: 0, 6-12:1...) |
进阶要点2:选择什么样的建模思路
1、按 did 聚合后的分层建模
核心思想:
将问题拆解为两层:用户层和事件层,通过分层建模捕捉用户级特征与事件级特征的交互。
具体步骤:
- 用户层建模:
- 对每个
did进行特征聚合(如行为频次、时间分布、RFM特征等),训练一个用户级模型(如LightGBM/XGBoost),预测该did的标签(或概率)。 - 例如:使用每个
did的累计行为次数、最近一次行为时间间隔等作为输入特征。
- 对每个
- 事件层建模:
- 在事件级别(即原始样本)引入用户级预测结果作为特征,构建混合模型。
- 例如:将用户级模型的输出(如预测概率)与事件级特征(如
eid、时间戳、设备信息)拼接,输入到最终模型(如神经网络或集成树)中进行预测。
优势:
- 用户层模型可捕捉全局用户行为模式,事件层模型可结合局部事件特征,提升模型鲁棒性。
- 对于测试集中重复的
did,用户层预测结果可直接复用,减少冗余计算。
2、半监督学习策略
核心思想:
利用测试数据中重复的 did (部分标签已知但不唯一)作为伪标签,结合训练数据进行半监督训练。
具体步骤:
- 筛选伪标签:
- 对测试集中重复的
did,若其在训练集中有多个样本且标签一致,可直接使用该标签作为伪标签。 - 若标签不一致,可通过以下方式处理:
- 投票机制:选择训练集中该
did的多数类标签。 - 置信度阈值:对预测概率较高的样本(如阈值>0.95)生成伪标签。
- 投票机制:选择训练集中该
- 对测试集中重复的
优势:
利用测试数据中的隐式信息(重复
did的已知标签),提升模型泛化能力。对标签不唯一的场景,通过置信度筛选降低噪声风险。
3、动态标签映射与修正
核心思想:
针对测试集中重复的 did ,动态修正其预测标签,结合训练数据中的历史行为模式。
具体步骤:
- 标签冲突检测:
对于测试集中某个
did,若其在训练集中有多个标签,统计标签分布(如出现次数、时间趋势)。例如:若某
did在训练集中同时存在0和1标签,但1标签集中在近期事件中,则优先选择1作为预测值。
- 动态修正策略:
时间加权平均:根据训练集中
did的标签时间分布,加权计算预测值。行为相似度匹配:将测试样本与训练集中该
did的相似行为样本匹配,提取标签分布。
优势:
精细化处理标签不唯一的场景,避免简单投票导致的偏差。
结合时间动态性和行为相似性,提升预测的合理性。
最终模型改进
用户层建模:(0.63->0.86)
- 对每个
did进行特征聚合(如行为频次、时间分布、RFM特征等),训练一个用户级模型(如LightGBM/XGBoost),预测该did的标签(或概率)。
- 对每个
修改模型调参空间(0.86->0.94)
- 参数固定(如
max_depth=12、num_leaves=63),未通过网格搜索或贝叶斯优化探索更优参数组合。
- 参数固定(如
解析udmap和联合其他特征做特征工程:(0.94-0.95)
- 未充分挖掘
udmap字段中的JSON信息
- 未充分挖掘
修复数据泄露问题
RFM特征是在 full_df 上聚合的,可能无意间“偷看了测试集”。我立即调整逻辑,确保所有特征只基于训练集统计。
📉 分数略降,但汇总能力更真实可靠!udmap 探掘 & 组合特征(0.94 ➔ 0.95)
开始深入 JSON 字段udmap,探索了botId,pluginId等关键信息,还构造了组合特征:device_brand + os_typehour+ 活跃时段
虽然提升不大,但对理解数据有很大帮助🧠
第五步:规则提分策略(0.95 ➔ 0.97)
670K测试用户里,**93%在训练集里出现过**——我灵机一動✨:
将 `did` 直接作为特征加入模型,让模型学会“重复用户 = 老用户 = 0” 的强规则
🚀 结果:F1爆炸提升至**0.97**!
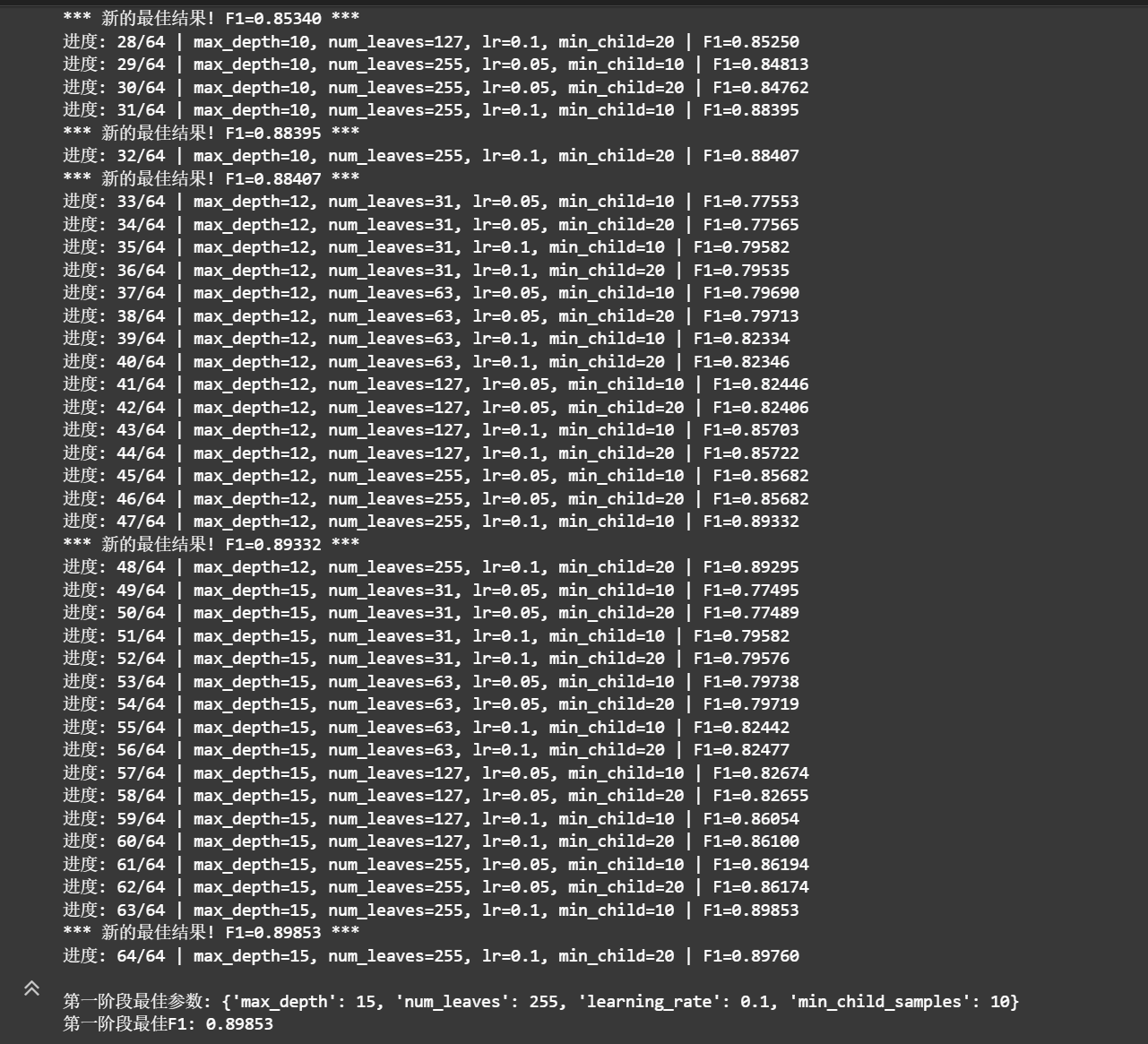
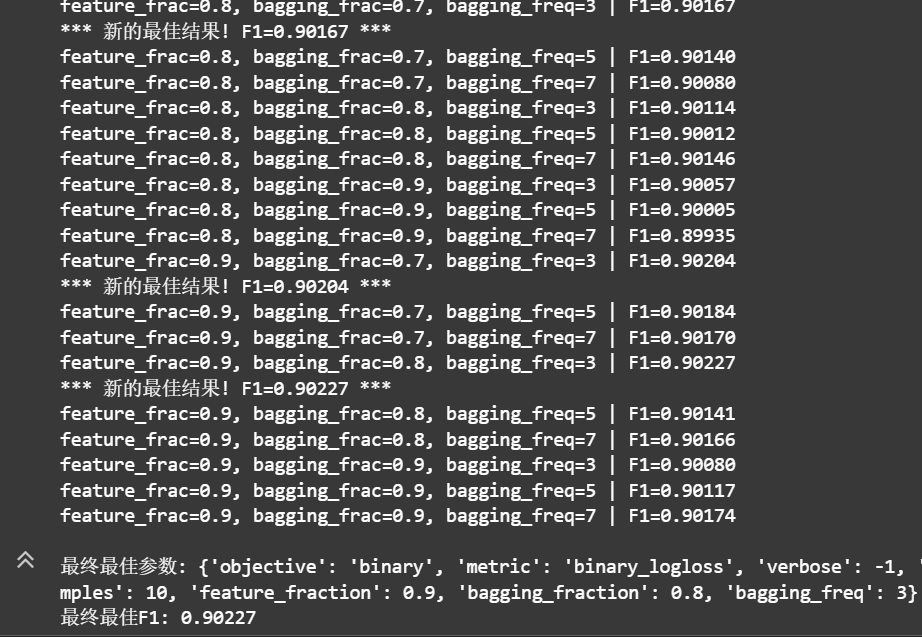
网格搜索 (Grid Search)
适用场景: 参数空间较小,需要全面探索
优势: 保证找到搜索范围内的最优组合
时间复杂度: O(n^k) - n为每个参数的候选值数,k为参数个数
实现: 分两阶段搜索,先结构参数后正则化参数
核心结构参数 (影响最大)
max_depth & num_leaves: 控制模型复杂度,防止过拟合
learning_rate: 控制训练速度和最终性能的平衡
min_child_samples: 叶子节点最小样本数,影响泛化能力
正则化参数 (精细调节)
feature_fraction: 特征采样比例,防止过拟合
bagging_fraction & bagging_freq: 样本采样,提高鲁棒性
特征的重要性:
一开始的相关性矩阵(如皮尔逊相关系数)可以提供一定的参考,但它不能充分或准确判断特征对模型预测的“重要性”,原因如下:
相关性只是线性关联:相关系数(如 Pearson)只衡量两个变量之间的线性关系。如果一个特征与目标变量有非线性关系(例如 U 型、对数型等),它可能在相关性矩阵中显示“相关性弱”,但在非线性模型(如 LightGBM)中却是一个重要特征。
不能考虑特征交互:相关性分析是逐个特征和标签的“单变量分析”,不考虑特征之间的联合作用。而像 LightGBM 这样的树模型可以利用多个特征之间的组合关系(交叉特征)来进行分裂和判断。
对目标变量的影响可能被遮蔽:某些变量与目标变量本身相关性不强,但它与其他强变量结合后具有很强的预测力。相关性矩阵无法体现这种“边际贡献”或“条件重要性”。
相关性矩阵可以用于初筛(如去除明显冗余的高度相关特征),但无法替代模型训练后的特征重要性分析。