超越提示词:深入理解AI应用的核心——上下文工程
当我们与AI大语言模型(LLM)互动时,常常会遇到一个瓶颈:为什么有时AI Agent在处理复杂任务时显得力不从心?答案可能并非模型本身的能力不足,而在于一个常被忽视的关键环节——**上下文工程(Context Engineering)**的失败。这篇笔记将带您深入探讨这一核心概念,理解它如何成为驱动AI Agent高效工作的“内存管理器”。
什么是“上下文”?它远不止聊天记录
首先,我们需要重新定义“上下文”。它并非简单指代我们与AI的对话历史,而是指提供给模型用于推理和生成下一步任务的“全部信息集合”。一个设计良好的上下文,通常包含三大核心类别: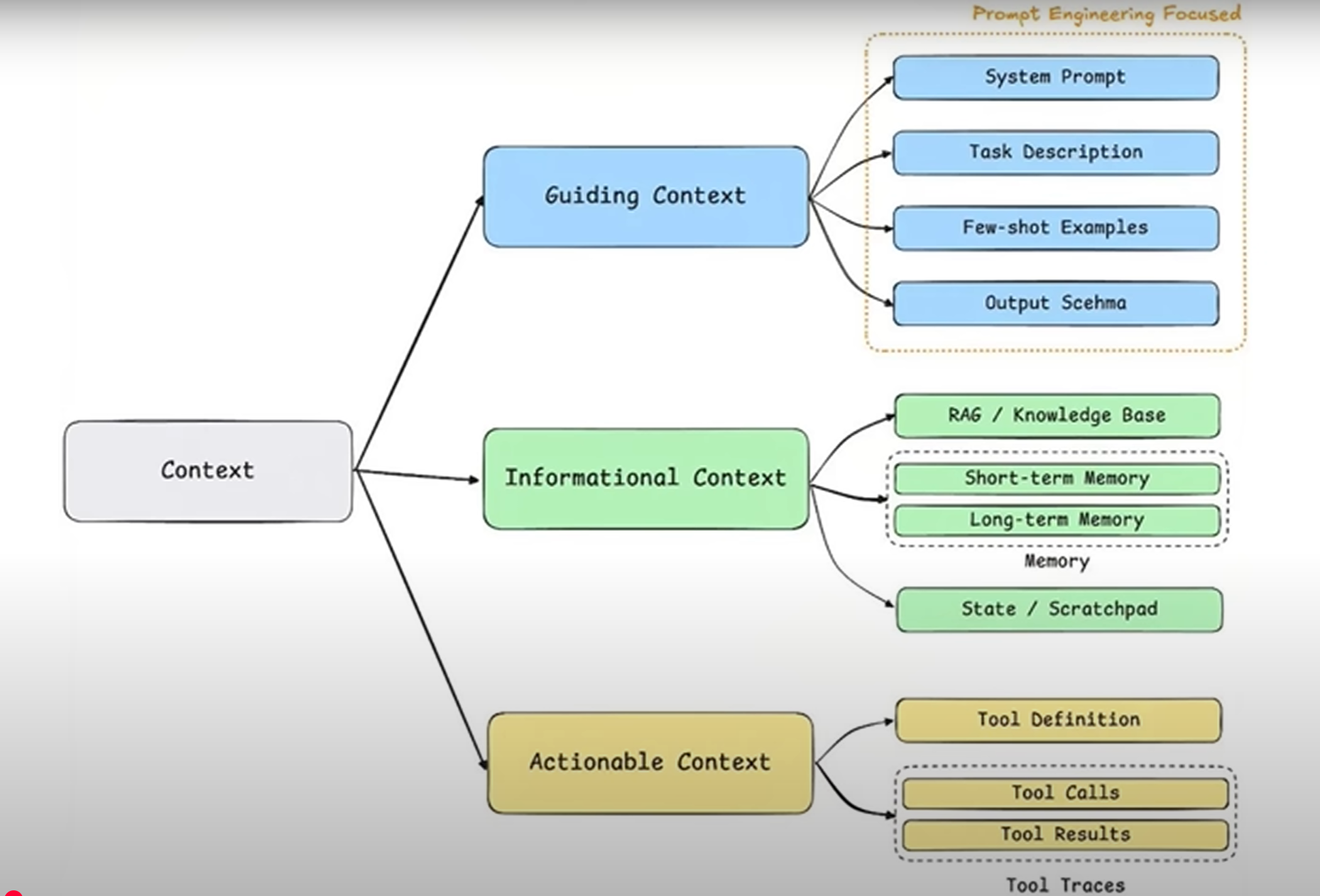
指导性上下文 (Guidance Context):这是我们最熟悉的领域,主要通过提示词工程(Prompt Engineering)来实现。它负责告诉模型“做什么”和“怎么做”,为任务设定框架、目标和规则,例如系统提示、任务描述和输出格式定义。
信息性上下文 (Informative Context):这部分内容旨在告诉模型“需要知道什么”,为它提供解决问题所需的关键事实与数据。它涵盖了我们常说的RAG(检索增强生成)技术,以及短期与长期记忆等。
行动性上下文 (Actionable Context):这部分赋予模型与外部世界交互的能力,告诉它“能做什么”以及“做了之后会发生什么”。它包括工具的定义、调用过程与结果反馈。
上下文工程:AI Agent的智能“内存管理器”
理解了上下文的构成后,“上下文工程”的定义便豁然开朗。它是一门系统性的学科,专注于设计、构建并维护一个动态系统。该系统的核心任务是:为Agent执行任务的每一步,智能地组装出最优的上下文组合,从而确保任务被高效、准确地完成。
一个绝佳的比喻是:如果把AI Agent看作一个操作系统,大语言模型是CPU,那么上下文窗口就是内存(RAM),而上下文工程就是这个系统的内存管理器。它精准地调度哪些数据应该被加载、哪些应该被换出、哪些应被优先处理,以保证系统流畅运行。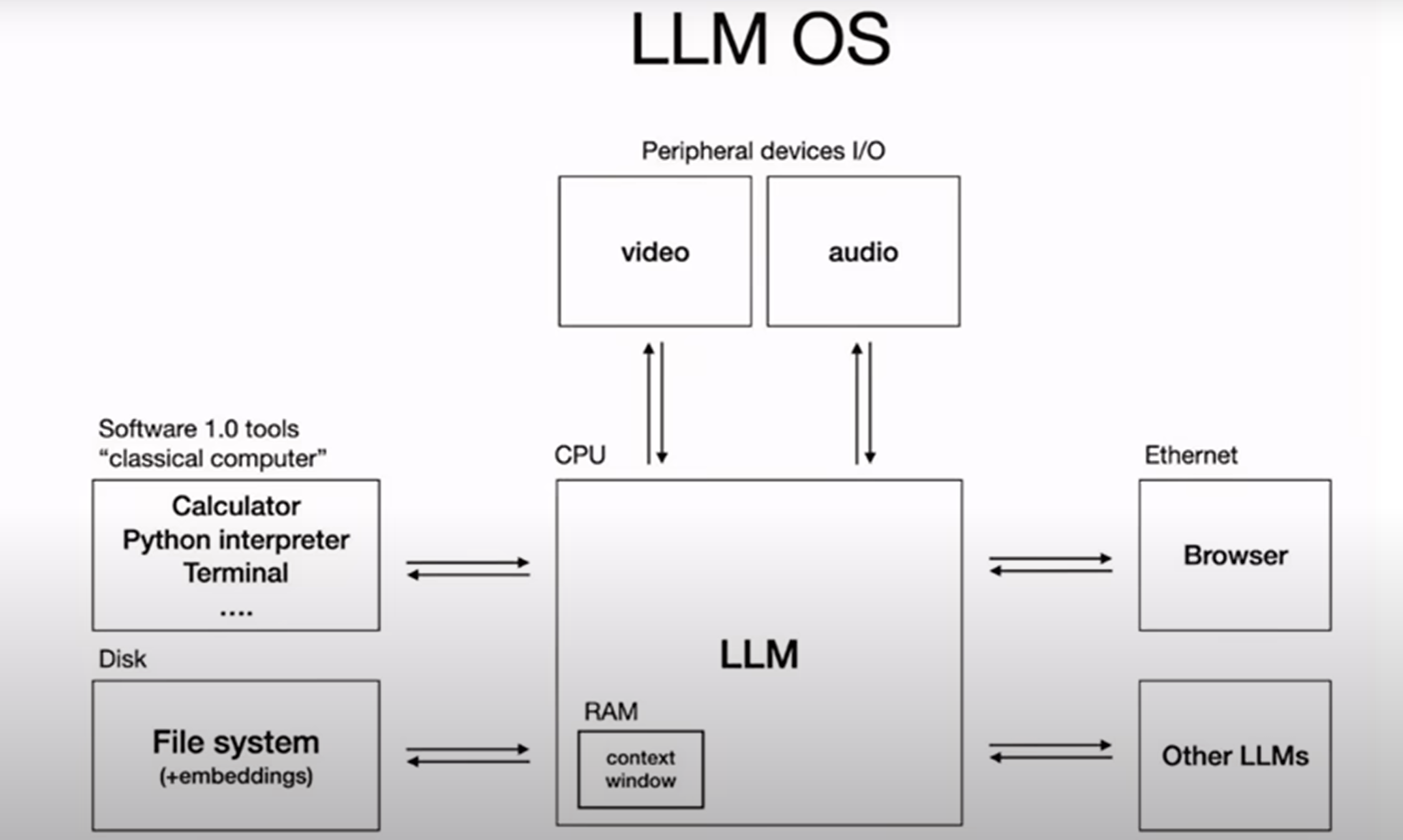
这标志着我们与AI交互模式的升级——从仅仅优化单次指令的“提示词工程”,迈向了构建一个高效信息供给系统的全新阶段。
应对挑战:上下文工程的四大核心策略
将所有信息一股脑地塞给模型显然是行不通的。这样做不仅会因信息过载导致性能下降和上下文干扰,还会急剧增加API调用的成本与延迟,甚至因超出上下文窗口长度而导致任务失败。
因此,上下文工程提出了四大核心策略来智能地管理信息流:
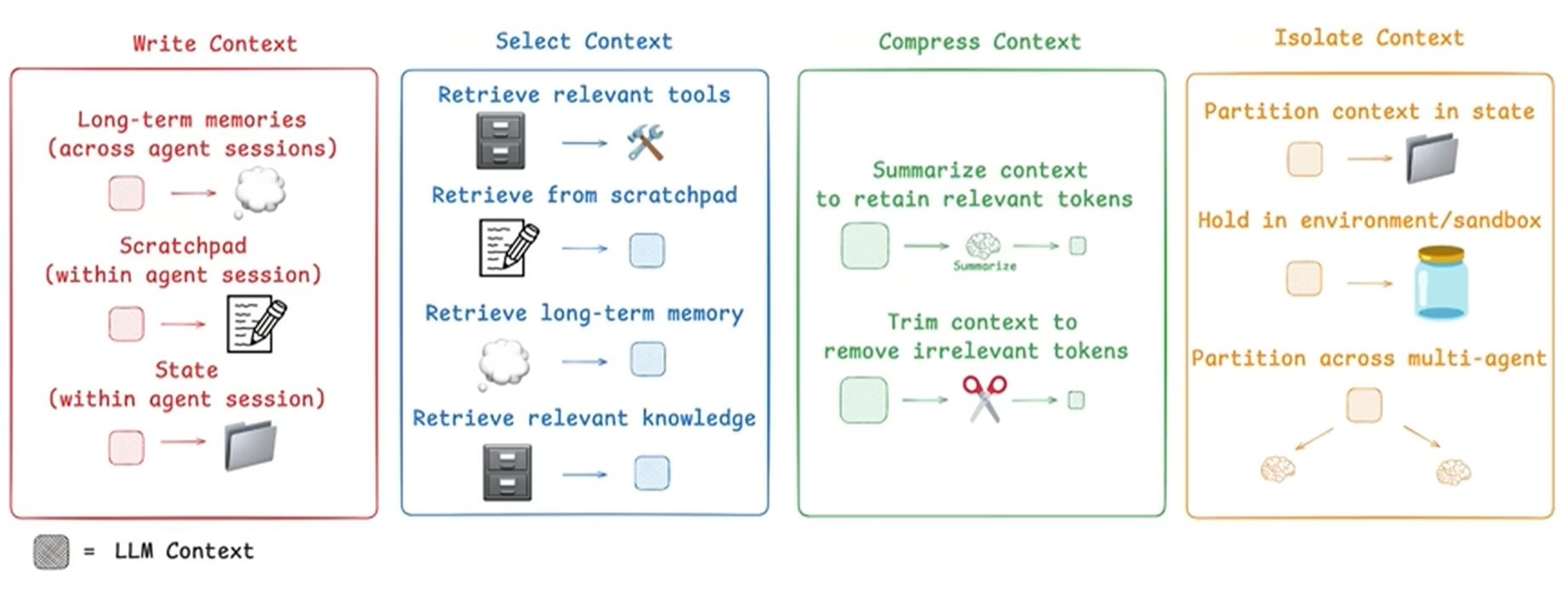
写入 (Write):将关键信息持久化存储,超越上下文窗口的限制。这包括将会话中的中间思考写入“草稿区”,或将具有长期价值的信息(如用户画像)存入外部记忆系统,让Agent能够跨会话学习与成长。
选取 (Select):在每次调用模型前,从所有可用的信息源中,动态地拉取与当前子任务最相关的信息。这是保证上下文信噪比、避免干扰的关键。无论是通过预设规则、模型驱动还是相似度检索(RAG),目的都是精准选取。
压缩 (Compress):在信息进入上下文窗口前,对其进行有损或无损的压缩,用更少的Token承载最核心的信号。例如,在上下文接近溢出时,系统可以自动对历史信息进行总结,或直接修剪掉部分内容。
隔离 (Isolate):在处理多条信息流时,设置边界,让子流程先行消化,仅向上层提交关键要点。这好比一个多Agent系统,每个子Agent在各自领域内并行工作,消化原始信息,然后将压缩后的洞见提交给主Agent,从而极大减轻主Agent的认知负担。工具调用和沙盒环境也体现了同样的隔离思想。
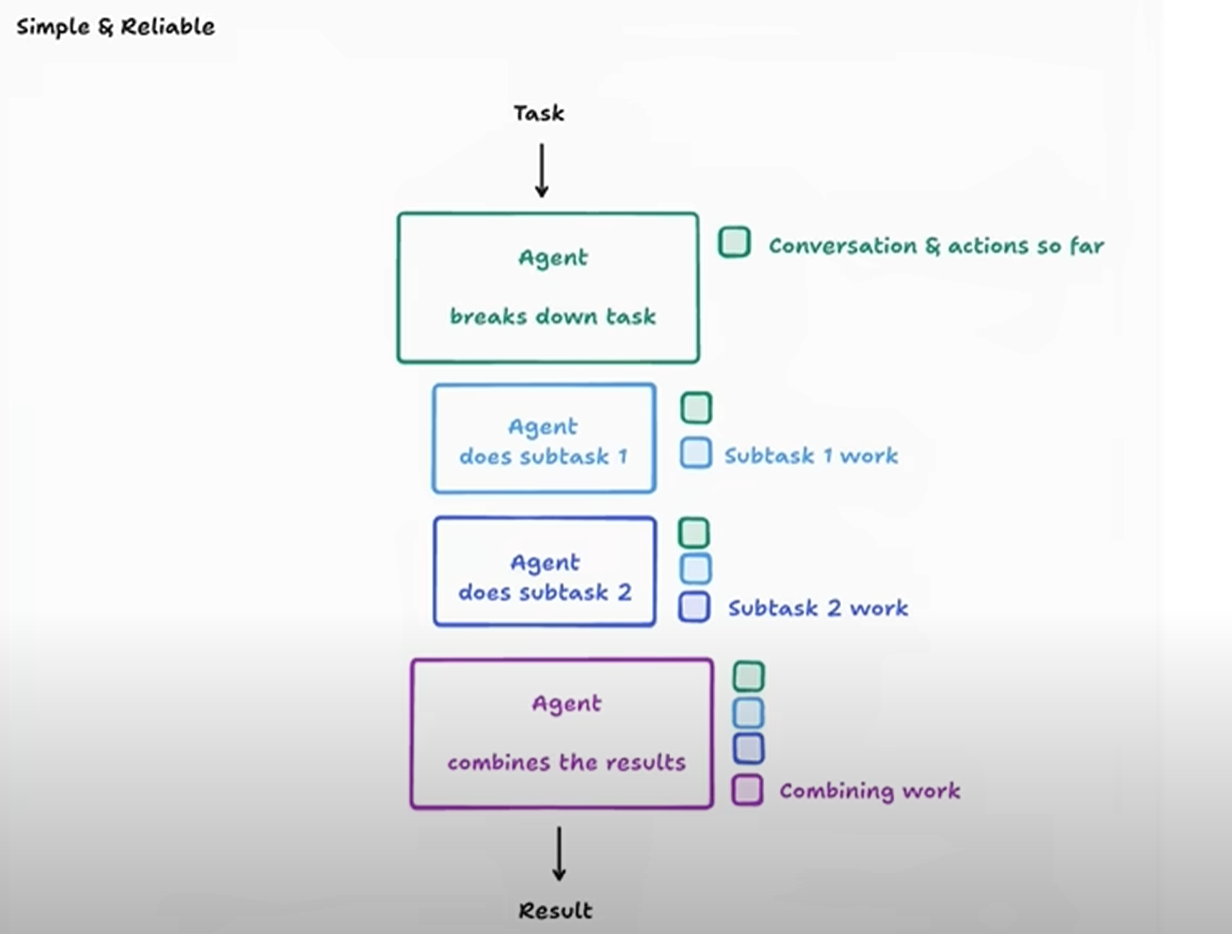
结论:从“完美提示词”到“健壮系统”
上下文工程并非一个故弄玄虚的新概念,而是AI应用从简单的演示走向工业级产品的必然演进。我们的开发重心正在不可逆转地从“如何找到那一句完美的提示词”,转向**“如何设计一个能为模型在每一步都动态组装出完美上下文的健壮系统”**。
熟练地运用“写入、选取、压缩、隔离”这四大策略,将是区分一个AI应用是有趣的玩具,还是一个可靠、可规模化产品的关键。最终,无论是精巧的提示词、高效的RAG系统,还是标准化的模型交互协议(MCP),它们都服务于同一个终极目标:在模型做出决策之前,为它准备好一份恰到好处的上下文。