
Python与Pytorch
1. enumerate
作用:在 遍历一个序列 时,额外提供 元素的索引。
语法:
1 | for i, x in enumerate(sequence, start=0): |
i是索引(默认从 0 开始,可以用start改起始值);x是序列里的元素。
例子:
1 | chars = ['a', 'b', 'c'] |
输出:
1 | 0 a |
用途:常用于 建立索引表(比如你代码里的 stoi),或者当你需要同时知道 位置 和 值 时。
2. zip
作用:把 多个可迭代对象(list/tuple/string等)里的元素 一一配对,返回元组。
语法:
1 | for x, y in zip(seq1, seq2): |
第一个序列的第
k个元素和第二个序列的第k个元素配成一对(x, y)。会在最短的序列结束时停下。
例子:
1 | a = [1, 2, 3] |
输出:
1 | 1 x |
用途:常用于 同时遍历多个列表,比如 bigram 的 (ch1, ch2) 配对就是用 zip(chs, chs[1:])。
3.torch.multinomial
1 | torch.multinomial(input, num_samples, replacement=False, *, generator=None) |
输入:
input是一个 非负向量(通常是概率分布)。维度是
n,也就是说有n个候选类别。
输出:
返回一个 tensor,里面是
0 ~ n-1之间的 索引。每个索引出现的概率,与
input中对应元素的大小成正比。如果
input已经归一化成概率(和为 1),那它就是一个标准的概率分布采样器。如果没归一化,也没关系,PyTorch 会按相对大小处理(相当于
input / input.sum())。
1 | import torch |
可能输出:
1 | tensor([0, 0, 1, 0, 2, 0, 1, 0, 0, 1]) |
解释:
类别
0(概率 0.7)最容易被抽中;类别
1(概率 0.2)偶尔出现;类别
2(概率 0.1)很少出现。
4. torch.sum
1 | torch.sum(input, dim=None, keepdim=False) |
input:要计算的张量。dim:在哪个维度上求和。如果不写,默认对所有元素求和,结果是一个标量。
如果指定
dim,会沿着这个维度加总。
keepdim:是否保持原来的维度数。
keepdim=False(默认)
会“压缩掉”那个维度。
例子:
1 | x = torch.tensor([[1,2,3], |
1 | torch.sum(x, dim=1) |
结果:
1 | tensor([ 6, 15 ]) # shape (2,) |
在 dim=1(横向)相加:
[1+2+3, 4+5+6]原来是 (2,3),变成 (2,)。维度减少了。
keepdim=True
会保留那个维度,只是把它变成大小为 1。
1 | torch.sum(x, dim=1, keepdim=True) |
结果:
1 | tensor([[ 6], |
仍然是二维矩阵 (2,1),不是 (2,)。
保持维度在广播(broadcasting)时很有用。
总结:
sum(dim=...):指定维度上加总。keepdim=False:压缩掉这个维度(默认)。keepdim=True:保留这个维度(变成 1),方便后续广播运算。
5.torch 广播机制:
当两个张量做逐元素运算(加减乘除等)时,PyTorch 会尝试“扩展”它们的形状 (shape)。
广播机制成立的条件是:
从最后一个维度开始对齐(右对齐原则)。
两个维度要么相等,要么其中一个是 1。
如果某一维不满足上面两个条件,就会报错。
扩展时不会真的复制数据,只是逻辑上重复。
例子解析
情况1:完全相等
1 | a = torch.ones(2,3) |
形状完全一致 → 可以逐元素运算。
情况2:有一个维度是 1
1 | a = torch.ones(2,3) # shape (2,3) |
情况3:标量参与运算
1 | a = torch.ones(2,3) |
情况4:高维与低维
1 | a = torch.ones(4,3,2) # shape (4,3,2) |
情况5:不兼容
1 | a = torch.ones(2,3) |
因为 dim=0:2 vs 4,不相等,也不是 1。
直观口诀
右对齐:从最后一维开始比较。
能配上就配(相等);
小的伸展(有 1 就扩展);
不合适就报错。
6.print的tip
print(f'{nll=}'):自动加上变量名,调试更方便(Python 3.8+)print(f'nll={nll}'):手动写了"nll=",然后拼接变量值。
Loss function的选择
1. 总目标
1 | # GOAL: maximize likelihood of the data w.r.t. model parameters (statistical modeling) |
统计建模的目标:在参数 θ 下,让模型生成观测数据的概率尽可能大。
公式:
2. 等价于最大化 log likelihood
1 | # equivalent to maximizing the log likelihood (because log is monotonic) |
因为
log是单调递增函数,最大化 likelihood 和最大化 log-likelihood 是等价的。直接相乘会数值下溢(很多概率 < 1,相乘结果趋近于 0)
log 可以把乘法变加法,数值更稳定。
3. 等价于最小化负对数似然
1 | # equivalent to minimizing the negative log likelihood |
在机器学习里我们习惯写 损失函数要最小化。
所以把最大化 log-likelihood 转换成 最小化负 log-likelihood (NLL):
4. 等价于最小化平均负对数似然
1 | # equivalent to minimizing the average negative log likelihood |
- 进一步,我们常常取平均,得到每个样本的平均损失:
这就是 交叉熵损失 (cross-entropy loss) 的来源。
神经网络的输入(将字符转化为向量):
1. 什么是 One-Hot 向量?
在 NLP 或分类任务中,我们常常需要把 离散的类别(如字符、单词、标签) 转换成向量。
如果类别数是 VV,那么 one-hot 向量就是长度为 VV 的向量:
只有 该类别对应的位置是 1,
其它位置全是 0。
例子:
词表大小 V=5V=5,假设类别是 2,
则 one-hot 表示为:
1 | [0, 0, 1, 0, 0] |
2. PyTorch 里的 one-hot 实现
常用方法是 torch.nn.functional.one_hot:
1 | import torch |
输出:
1 | tensor([[1, 0, 0, 0], # 类别0 → one-hot |
输入:索引张量(shape =
[N]或更高维)。输出:one-hot 张量(shape =
[N, num_classes])。
3. 在语言模型里的作用
假设词表大小 V=27V=27,
输入字符索引 =
5(对应 ‘e’),它的 one-hot 表示就是
[0,0,0,0,0,1,0,...,0],长度 27。
这样模型(比如线性层)就能直接用矩阵乘法处理离散符号。
4. 注意事项
One-hot 向量维度很大(词表越大,向量越稀疏)。
在实际 NLP 中,更常用 embedding 向量 替代 one-hot:
Embedding 把每个词映射到一个低维稠密向量(比如 300 维),
比 one-hot(几万维)更高效、更能捕捉语义。
logit,log-count,bigram
统计 bigram 和 神经网络 bigram
1. 在 bigram 统计模型里
我们有计数矩阵 NN:
然后做概率估计:
如果取对数:
所以 log-count 就是对“次数”的 log 变换。
2. 在神经网络 bigram 里
我们定义一个线性层:
输入
:one-hot(比如字符 m)。权重矩阵
。 结果 z=W[i]z = W[i](one-hot 只会挑出对应行)。
因此:
每一行 W[i] 就对应于“当输入是字符 i 时,所有可能输出的 raw score(原始打分)”。
这组 raw score = logits。
3. 为什么可以类比成“log-count”?
统计模型:
用 N[i,j](次数)来估计转移概率。
次数多 → 概率大 →
也大。
神经网络:
用参数矩阵 W[i,j] 来学这个关系。
训练的目标是:让 softmax(W[i]) 给出的概率分布,最大化数据的 log-likelihood。
结果:W[i,j]会学到一个值,它的大小和“训练数据里 i→j 出现的多寡”正相关。
exp 恢复:
在 softmax 里用
,可以把 解释成“伪 log-count”。 换句话说,
是模型学到的 次数的对数近似值。
4. 更直观的比喻
统计 bigram:
我真的数数:
ma出现 100 次,mb出现 5 次。所以
。
神经 bigram:
我不直接存次数,而是存一个参数
,经过训练,优化目标会让它学到一个数, 大约对应于“100 的 log 比 5 的 log 大很多”。
这样 softmax(exp(logits)) 出来的概率就和数频率很像。
5. 回答你的疑惑
“为什么 logit 只是矩阵乘法结果,怎么就和次数的对数有关系了?”
因为:
在统计模型里,log-count 是直接数出来的;
在神经网络里,logit 是参数矩阵学出来的数,训练目标就是让它模拟 log-count 的效果。
所以 logit 不是一开始就等于 log-count,而是经过训练,逐渐拟合到“和 log-count 相似的表示”。
平滑手段:
1. 前面的 +1 (count smoothing)
在统计语言模型里(比如 bigram 计数),我们经常会看到 加 1 平滑 (Laplace smoothing):
作用:避免某些组合没见过 → 概率变成 0。
它是对 数据层面的计数 做修正,让概率分布更“均匀”一些。
2. 这里的 正则化项
在神经网络训练时,loss 变成:
1 | loss = -probs[torch.arange(num), ys].log().mean() + 0.01 * (W**2).mean() |
第一项:负对数似然(cross-entropy),就是标准的最大似然训练。
第二项:
这就是 L2 正则化(也叫权重衰减)。
作用:
惩罚权重 W 过大。
鼓励网络学到的参数更小、更平滑,不会对某个输入过度“极端”地放大某个类别。
从概率角度看,它也让输出的分布更均匀(不至于某个概率特别接近 1,其他全是 0)。
3. 对比这两者的“平滑”作用
+1smoothing:在 数据统计 里防止概率为 0。L2 正则化:在 参数训练 中防止权重爆炸,让模型输出更平滑。
所以它们思想类似(都让分布不要太极端),但切入点不同:
+1是在 count 层面做平滑;L2 正则是通过 限制参数规模 来间接平滑输出分布。
项目的逻辑
从零开始构建语言模型:Andrej Karpathy 的 makemore 项目
Andrej Karpathy 详细介绍了一个名为 makemore 的项目,这是一个基于字符的语言模型。它的目标是生成那些听起来像是真实单词,但实际上是全新创造的词汇。
makemore 是什么?
makemore 的核心是一个字符级语言模型。这意味着它不是处理整个单词,而是一次处理一个字符序列。例如,对于单词“Reese”,模型会将其看作是一系列独立的字符(R、e、e、s、e)。模型通过学习这些序列,来预测下一个可能出现的字符,从而生成全新的词汇。
Karpathy 在视频中提到,这个系列将涵盖多种不同复杂度的字符级语言模型,包括:
二元模型 (Bi-gram models)
词袋模型 (Bag-of-words models)
多层感知器 (Multilayer Perceptrons)
循环神经网络 (Recurrent Neural Networks)
现代 Transformer 模型
他甚至计划在后续内容中,构建一个类似于 GPT-2 的 Transformer 模型。这个项目的最终目标,是从字符级模型逐步扩展到词级模型,甚至可能探索图像和图文网络(例如 DALL-E 和 Stable Diffusion)。
数据准备与二元模型
视频首先加载了一个名为 names.txt 的数据集,其中包含了大约 32,000 个名字。数据集经过清理,并被转换成了一个 Python 字符串列表。通过对数据集的分析,我们发现其中最短的单词由 2 个字符组成,而最长的则有 15 个字符。
Karpathy 强调,每一个单词都包含了多个学习样本。例如,在单词“isabella”中,我们可以学到“i”很可能是一个名字的开头,而“s”很可能跟在“i”的后面,依此类推。此外,每个单词的结尾(例如,“isabella”后面的结束标记)也为模型提供了重要的统计信息。
为了简化问题,从一个二元语言模型开始。二元模型只考虑两个字符之间的关系:给定一个字符,它会预测下一个最有可能出现的字符。虽然这是一个非常简单且能力有限的模型,但它却是理解语言模型基本概念的绝佳起点。
为了实现这一点,Karpathy 展示了如何使用 Python 的 zip 函数来生成单词中连续的字符对(即二元组)。为了能够捕捉到单词的开始和结束,他还引入了特殊的起始和结束标记。例如,用 . 后跟 ‘e’ 来表示 Emma 的第一个字符,用 ‘a’ 后跟 . 来表示 Emma 的最后一个字符。
统计计数与 PyTorch 张量
接下来,通过计算数据集中每个二元组出现的频率来学习统计信息。这些计数最初被存储在一个 Python 字典中。为了更方便地进行数学运算,这些计数随后被转移到了一个 PyTorch 的二维张量 N 中。
Karpathy 详细解释了 PyTorch 张量的使用。PyTorch 是一个强大的库,用于高效地处理多维数组。他创建了一个 28x28 的张量(26 个字母加上起始和结束标记),并使用字符到整数的映射 (s2i) 和反向映射 (i2s) 来填充这个张量。
通过可视化这个 N 张量,我们可以清楚地看到不同字符对出现的频率。例如,某些行或列是全零的,因为某些二元组(例如以结束标记开头的二元组)在数据集中从未出现过。为了优化和美化这个表示,起始和结束标记被合并成了一个特殊的标记 .,从而将张量的大小减小到了 27x27。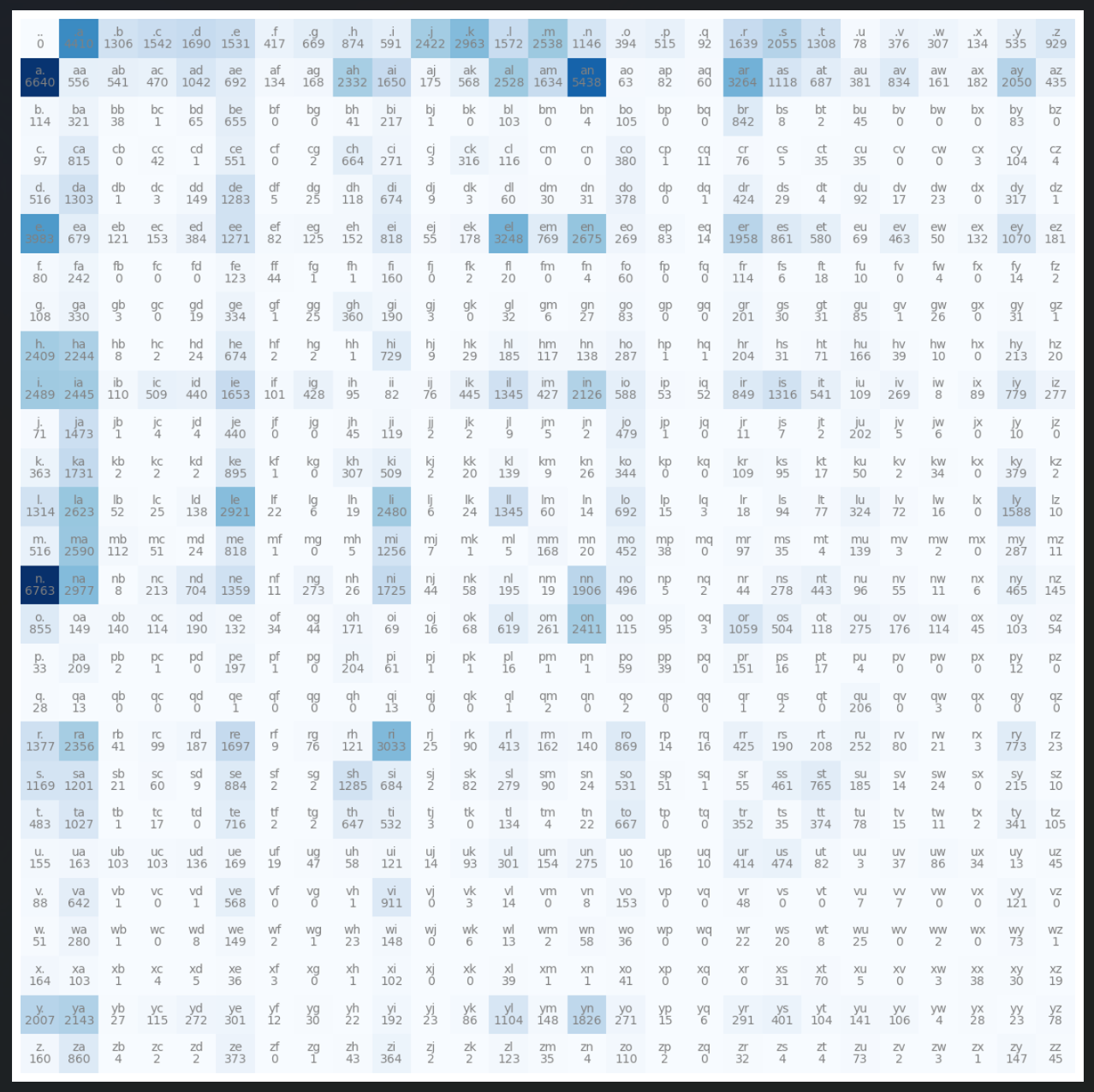
采样与模型评估
这个 N 张量包含了从我们的二元字符级语言模型中进行采样所需的所有信息。通过从代表起始标记 . 的那一行中进行采样,我们就可以预测出一个名字的第一个字符。
Karpathy 解释了如何将原始的计数值转换成概率分布。这需要将每个计数值除以其所在行的总和,以确保每一行的概率之和为 1。然后,他使用 torch.multinomial 函数从这些概率分布中进行采样。
为了确保实验结果的可复现性,他使用了 PyTorch 的生成器对象,并设定了随机种子。通过这个过程,模型就能够生成新的单词。然而,正如视频中所示,这些生成的单词(例如“mor”、“konge”等)质量非常差,这也凸显了二元语言模型固有的局限性。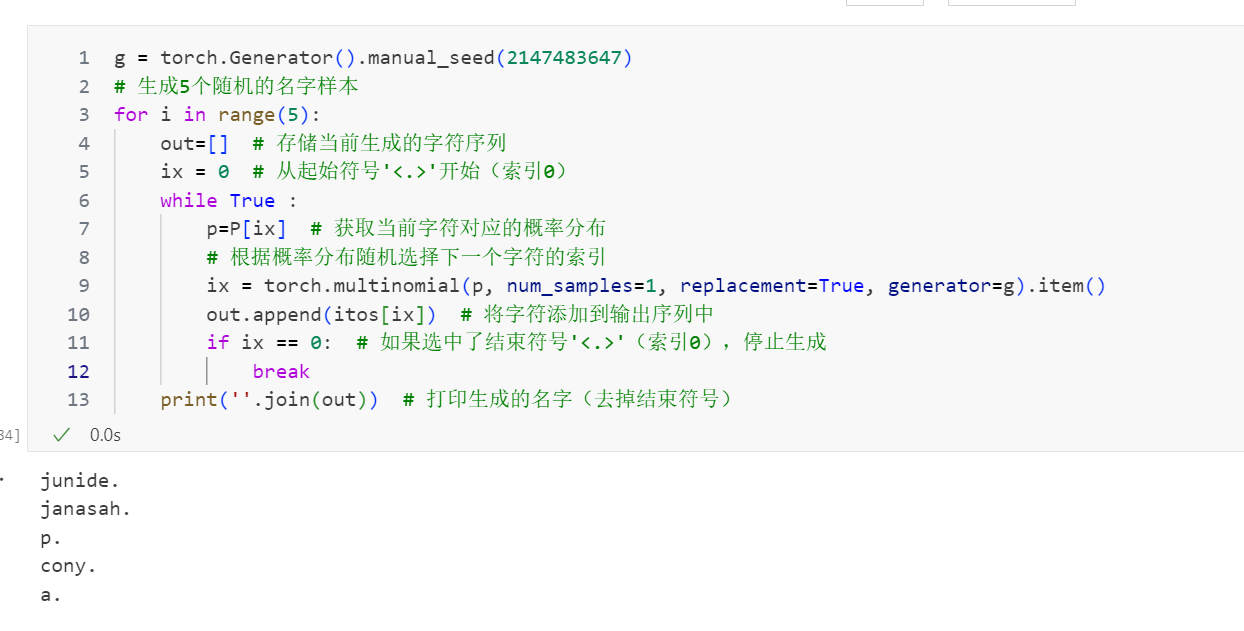
为了评估模型的质量,引入了损失函数的概念。模型的质量是通过计算训练集上每个二元组的对数似然 (Log-likelihood) 来衡量的。对数似然越高,模型就越好。负对数似然 (Negative Log-likelihood, NLL) 是一个常用的损失函数,我们的目标就是最小化这个 NLL。
NLL 的一个问题是,如果模型为某个二元组分配了零概率,那么损失就会变成无穷大。为了解决这个问题,视频引入了模型平滑技术,即在所有计数值上都加上一个小的“假”计数(例如 1)。这确保了没有任何二元组的概率为零,从而避免了无限损失的问题。
神经网络框架下的语言建模
后半部分将二元字符级语言模型的问题,重新定义为了一个神经网络框架。在这种方法中,神经网络接收单个字符作为输入,并输出下一个字符的概率分布。
训练集由二元组的输入字符和目标字符组成,它们都被转换成了整数。为了将这些整数输入到神经网络中,它们被进行了**“独热编码”(One-hot encoding)**。这意味着每个整数都被转换成了一个向量,其中对应索引位置的元素为 1,其余所有元素都为 0。Karpathy 强调,确保数据类型为浮点数非常重要,因为神经网络通常需要浮点数作为输入。
这个神经网络本身从一个简单的线性层开始,其中包含 27 个神经元(对应 27 个可能的字符)。这个线性层执行输入向量和权重矩阵之间的矩阵乘法。神经网络的输出被解释为**“logits”**(对数计数)。然后,这些 logits 被指数化以获得“计数”,并对这些计数进行归一化以获得概率分布(这个过程被称为 Softmax)。Softmax 层确保输出的概率值为正,且它们的总和为 1。
神经网络的训练是通过梯度下降优化来完成的。损失函数是平均负对数似然,模型的参数(即权重矩阵 W)会通过反向传播进行调整,以最小化这个损失。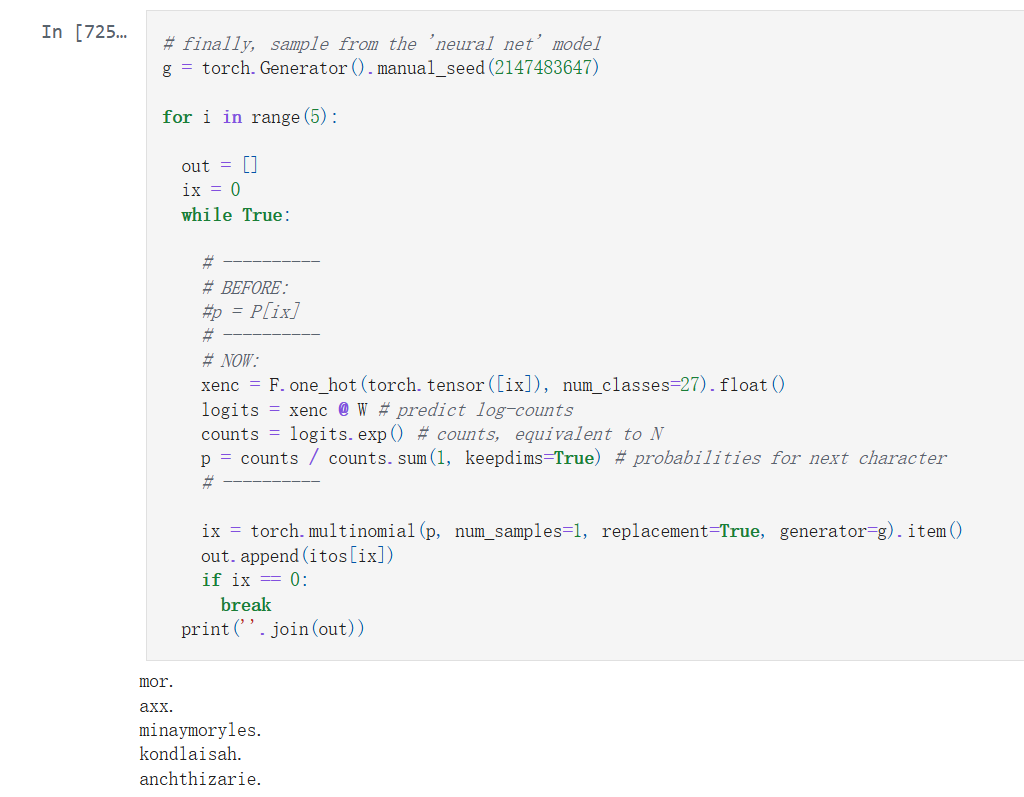
广播、正则化与可扩展性
Karpathy 深入探讨了 PyTorch 中的广播 (Broadcasting) 机制,这是一个在不同形状的张量之间执行操作的强大功能。他提醒说,如果不仔细理解广播规则,可能会导致难以发现的错误,例如在归一化概率时,意外地对列而不是行进行了归一化。
神经网络方法的一个关键优势在于其灵活性和可扩展性。虽然二元模型可以通过显式计数达到类似的性能,但神经网络方法可以轻松扩展到处理更复杂的模型,例如考虑更多个先前的字符来预测下一个字符(即拥有更大的上下文窗口)。
最后,Karpathy 介绍了正则化 (Regularization),这是一种通过在损失函数中添加惩罚项来平滑模型的方法。例如,通过将权重的平方和添加到损失中,可以鼓励权重接近于零,从而使模型输出更均匀的概率分布,这类似于传统模型平滑技术的效果。
总而言之,这段视频不仅构建了一个二元字符级语言模型,还展示了两种不同的训练方法(计数法和梯度下降法),并着重强调了神经网络方法在处理更复杂模型时的可扩展性和灵活性。