Homework-baseline Q&A
作业的 baseline 中看到 loss 在训练过程中不收敛,甚至来回震荡,通常是由以下几个核心原因造成的,其中学习率(Learning Rate)过高是最常见的主谋。
1. 学习率 (Learning Rate) 过高
现象:Loss 在训练初期迅速下降,但很快就开始在一个较高的值附近剧烈震荡,甚至可能突然增大(发散)。
原理:想象一下你正在下山(寻找 loss 的最低点)。学习率决定了你每一步迈出去的“步子”有多大。
- 如果步子太大(学习率过高),你可能一步就迈过了山谷的最低点,跑到了对面更高的山坡上。下一步你再往回迈,又可能再次越过最低点。如此反复,你就在谷底来回“横跳”,永远无法稳定在最低点。
解决方案:
调低学习率:这是最直接的方法。尝试将当前的学习率降低一个数量级,例如从
0.01降到0.001,或者从1e-4降到1e-5,看看 loss 曲线是否变得平滑并持续下降。使用学习率衰减 (Learning Rate Decay):在训练初期使用较大的学习率让模型快速收敛,随着训练的进行,逐渐减小学习率,让模型可以在最低点附近进行“精细微调”,从而稳定下来。
2. 数据未进行标准化或归一化 (Normalization/Standardization)
现象:Loss 下降非常缓慢,或者在下降过程中很不稳定。
原理:如果你的输入特征(Features)数值范围差异巨大(例如,一个特征在 0-1 之间,另一个在 1000-10000 之间),会导致损失函数的“等高线图”变成一个非常扁长的椭圆形。在这样的“地形”上,梯度下降算法会走很多“冤枉路”,更新方向会来回摇摆,很难高效地找到最低点。
解决方案:
标准化 (Standardization):将每个特征的数据都处理成均值为 0,标准差为 1 的分布。这是最常用的方法。
归一化 (Normalization):将每个特征的数据缩放到一个固定的范围,比如 [0, 1] 或 [-1, 1]。
检查 Baseline 代码:确保你理解并正确地运行了数据预处理的部分。通常 baseline 会提供这部分代码,但需要你用训练集的均值和标准差去处理验证集和测试集,而不是对每个数据集单独计算。
3. Mini-Batch 带来的噪声
Baseline 代码通常使用 Mini-Batch Gradient Descent 进行训练,而不是一次性将所有数据喂给模型。
现象:你看到的 loss 是在每个 batch 计算后打印出来的,它本身就是有噪声的,所以会上下波动。
原理:每个 mini-batch 只是全体数据的一个小子集,用它计算出的梯度只是对“全局真实梯度”的一个近似估计。因此,每个 batch 之间的 loss 有波动是完全正常的。我们真正关心的是整体趋势是否在下降。
解决方案:
观察 Epoch Loss:不要只看每个 step/batch 的 loss。你应该计算并观察每个 epoch (所有 batch 跑完一遍) 的平均 loss。这个值应该呈现出平滑下降并最终收敛的趋势。
观察验证集 Loss (Validation Loss):验证集 loss 更能反映模型的泛化能力,并且由于它通常是在整个验证集上计算的,所以曲线会比训练过程中的 batch loss 平滑得多。如果验证集 loss 能够稳定下降并收敛,那你的模型训练就是健康的。
4. 其他可能原因
数据本身有脏数据/异常值 (Outliers):某些样本的数值特别异常,会导致计算出的梯度突然变得很大,让模型“学歪了”,引起 loss 剧烈波动。
Batch Size 过小:过小的 Batch Size 会导致梯度估计的方差过大,使得训练过程震荡更剧烈。可以尝试适当增大 Batch Size。
代码 Bug:检查一下你在实现模型、损失函数或梯度更新时是否有笔误。
特征值选取(sklearn)
1 | def select_feat(train_data, valid_data, test_data, select_all=True): |
如何选特征:
1 | import pandas as pd |
.scores_告诉你每个特征的“分数”是多少,让你知道每个特征与目标值的相关性强弱。.get_support()告诉你哪些特征“被选中”了,是一个直接的结果。
最终改后代码:

最后k=17是bossline
修改网结构和修改优化器
原本模型可能层数少、每层维度小,无法学习足够复杂的映射关系。
1 | class My_Model(nn.Module): |
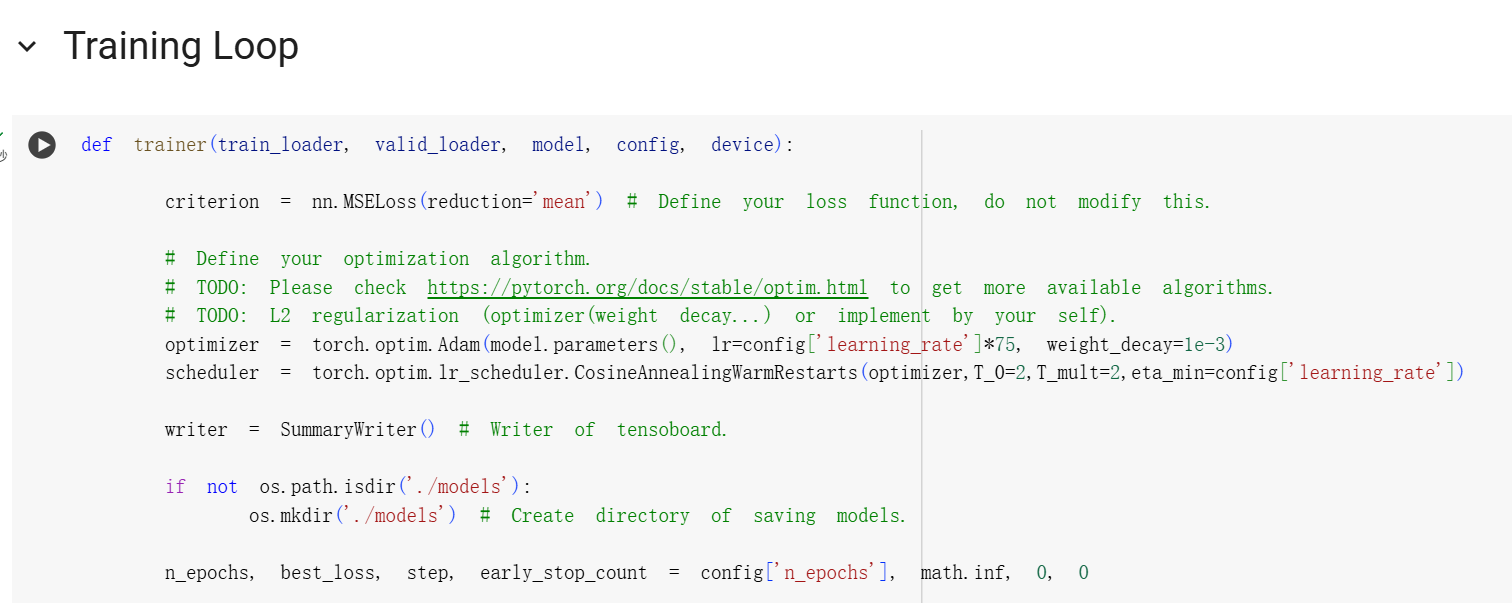
1 | def trainer(train_loader, valid_loader, model, config, device): |
1. 修改神经网络结构
做了什么:
它定义了一个包含三个全连接层 (
nn.Linear) 的神经网络。结构是:输入层 → 隐藏层1 → 隐藏层2 → 输出层。
网络宽度/神经元数量:
nn.Linear(input_dim, 64):接收输入数据,并将其转换为一个64维的向量(第一层有64个神经元)。nn.Linear(64, 16):接收上面的64维向量,并压缩成一个16维的向量(第二层有16个神经元)。nn.Linear(16, 1):接收16维向量,并最终输出1个数值(用于回归预测)。
激活函数:在层与层之间使用了
nn.ReLU(),这是为了给模型增加非线性能力,让它可以学习更复杂的数据模式。
| 任务类型 | 推荐层数 | 说明 |
|---|---|---|
| 简单回归 / 分类(结构化数据) | 1–3 层 | 64 → 16 → 1 是经典配置 |
| 特征维度大 / 非线性强 | 3–5 层 | 可以逐层减少宽度,如 128 → 64 → 32 → 8 |
| 图像分类(CNN) | 10 层以上 | 可用 ResNet、VGG 等已有结构 |
| 文本分类(Transformer) | 通常 ≥ 6 层 encoder | 层数越多捕捉的语义越深 |
2. 修改优化器和学习率
做了什么:-
weight_decay=1e-3相当于 L2 正则化,有助于缓解过拟合。- 更换优化器:原始方案用的是SGD(随机梯度下降法)。新的代码
optimizer = torch.optim.Adam(...)启用了 Adam 优化器。 - Adam 优化器融合了动量(momentum)与自适应学习率(AdaGrad 思想),在大多数任务中比 SGD 收敛更快、更稳定;
- 更换优化器:原始方案用的是SGD(随机梯度下降法)。新的代码
3.学习率
- 原先使用
1e-5的学习率太小导致“无法收敛”,即模型更新步伐太小,训练效果几乎没有提升;
CosineAnnealingWarmRestarts:
余弦退火调度器让学习率逐步减小(从高值逐步衰减到 eta_min);
WarmRestarts机制:每隔一定轮数重新将学习率拉高,有助于跳出局部最优;T_0=2, T_mult=2表示第一次退火周期为2轮,每次重启周期翻倍。
学习率乘以 75?
表明默认学习率(如 1e-5)太小,收敛太慢或模型停滞;
放大初始学习率后再用 cosine 调度衰减,更灵活地调控收敛速度
最终改后代码: