

Panel data
pandas = “Panel data” (面板数据)。
它指的是:对多个研究对象(如个人、公司、国家等)在多个时间点上进行观测的数据集合。换句话说,面板数据同时具有 横截面维度(不同个体)和 时间序列维度(不同时间),因此也称 纵向数据(longitudinal data)。
Series
在 pandas 里,Series 对象确实支持 布尔索引(boolean indexing)。原理是:当你对 Series 执行一个逻辑判断(例如 < 2000),它会返回一个与该 Series 等长的布尔序列(True/False),然后你可以用这个布尔序列去筛选数据。
例子
1 | import pandas as pd |
输出:
1 | 0 True |
此时 mask 就是一个布尔 Series。
再把它作为索引传回去:
1 | filtered = s[mask] |
输出:
1 | 0 1500 |
一步到位写法
1 | filtered = s[s < 2000] |
结果同上,直接返回所有小于 2000 的元素。
DataFrame
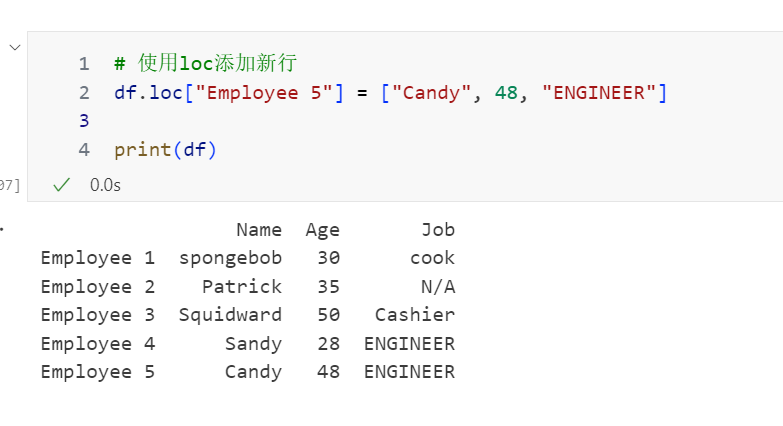
1. 加行(row-wise append)
本质:在 纵向(index 方向) 增加数据。
索引扩展:新行会有一个新的 index,需要与现有列的数量和顺序保持一致。
常用方法:
df.loc[new_index] = [value1, value2, ...]df.append(new_row, ignore_index=True)(新版本推荐pd.concat)
场景:比如你要往学生成绩表里加一个新同学的数据。
例子:
1 | import pandas as pd |
2. 加列(column-wise add)
本质:在 横向(columns 方向) 增加数据。
列名扩展:新列会有一个新的 column name,其长度必须与行数相同(或是一个标量自动广播)。
常用方法:
df["NewCol"] = [...]df.insert(position, "NewCol", data)
场景:比如在成绩表里加一列 “班级”。
例子:
1 | # 加列 |
3. 区别总结
- 方向不同:加行 → 扩展 index;加列 → 扩展 columns。
Selection
在 Pandas 中,数据选择方式主要有以下几类,可以根据需求灵活使用:
按列名选择
直接通过列名索引:
df["col"]或df[["col1", "col2"]]适合快速获取某一列或多列数据。
按行标签选择(
.loc)用法:
df.loc[行标签, 列标签]可以通过 行/列的名称 来选取数据。
例子:
1
2
3df.loc["row1", "col1"] # 取单个元素
df.loc["row1", ["col1","col2"]] # 取一行的多个列
df.loc[["row1","row2"], :] # 取多行所有列
按整数位置选择(
.iloc)用法:
df.iloc[行位置, 列位置]完全基于 行号/列号的整数下标。
例子:
1
2
3df.iloc[0, 1] # 第一行第二列
df.iloc[0:3, :] # 前三行所有列
df.iloc[:, [0, 2]] # 所有行的第1和第3列
布尔索引
用条件筛选:
df[df["col"] > 2000]可以与
.loc结合:df.loc[df["score"] > 90, "name"]
混合选择
.loc和.iloc可以和布尔条件/切片组合使用,非常灵活。