
Jensen’s inequality

注释:函数值的平权大于函数点的平均
Non-negativity of KL-Distance
Maximum Entropy Theorem最大熵定理
用KL-distance 非负性推出
KL 散度总是非负:
展开:
注意
因此:
等号条件
当 P=U即 X 服从均匀分布时),KL 散度为零,上界取到:
严格凹函数 ⇒ 极值唯一
我们已经知道
是 严格凹函数(因为每个项
对一个严格凹函数 f,若在凸约束集上(如概率单纯形)存在驻点,则该驻点是唯一的全局最大值。
换句话说:
严格凹+线性约束⟹唯一的最大点。
这里的 |X|代表什么
实际上这里的 ∣X∣ 是指 随机变量 X 能取的不同取值的数量,也就是它的样本空间的基数(cardinality)。
KL散度和互信息的区别:
| 层级 | KL 散度 | 互信息 |
|---|---|---|
| 样本空间 | 一维 |
二维 |
| 比较对象 | 真实分布 vs 模型分布 | 真实联合分布 vs 假设独立分布 |
| 几何意义 | 衡量“两个分布的距离” | 衡量“真实相关性偏离独立的程度” |
| 信息含义 | 模型误差 | 变量间共享信息 |
Log sum inequality

Convexity of KL-distance

Convexity of Mutual Information(重点)
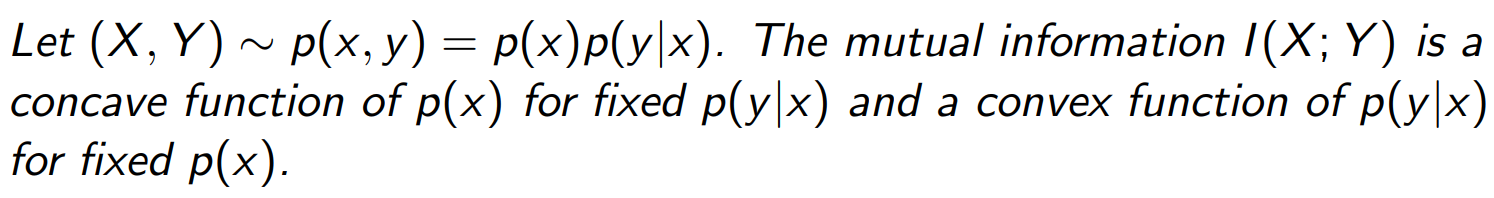
我们考虑一个随机变量对 (X, Y),它的联合分布由 边缘分布 p(x)(输入的分布)和 条件分布 p(y|x)(信道或传输规律)共同决定。
互信息 I(X; Y) 描述 X 与 Y 之间的信息量。 它对输入分布 p(x) 呈 凹函数(concave),对信道分布 p(y|x) 呈凸函数(convex)。
总结凹凸性:
| 函数 | 依赖变量 | 凹/凸性质 | 原因 |
|---|---|---|---|
| 凹(concave) | |||
| 联合 凸(convex) | |||
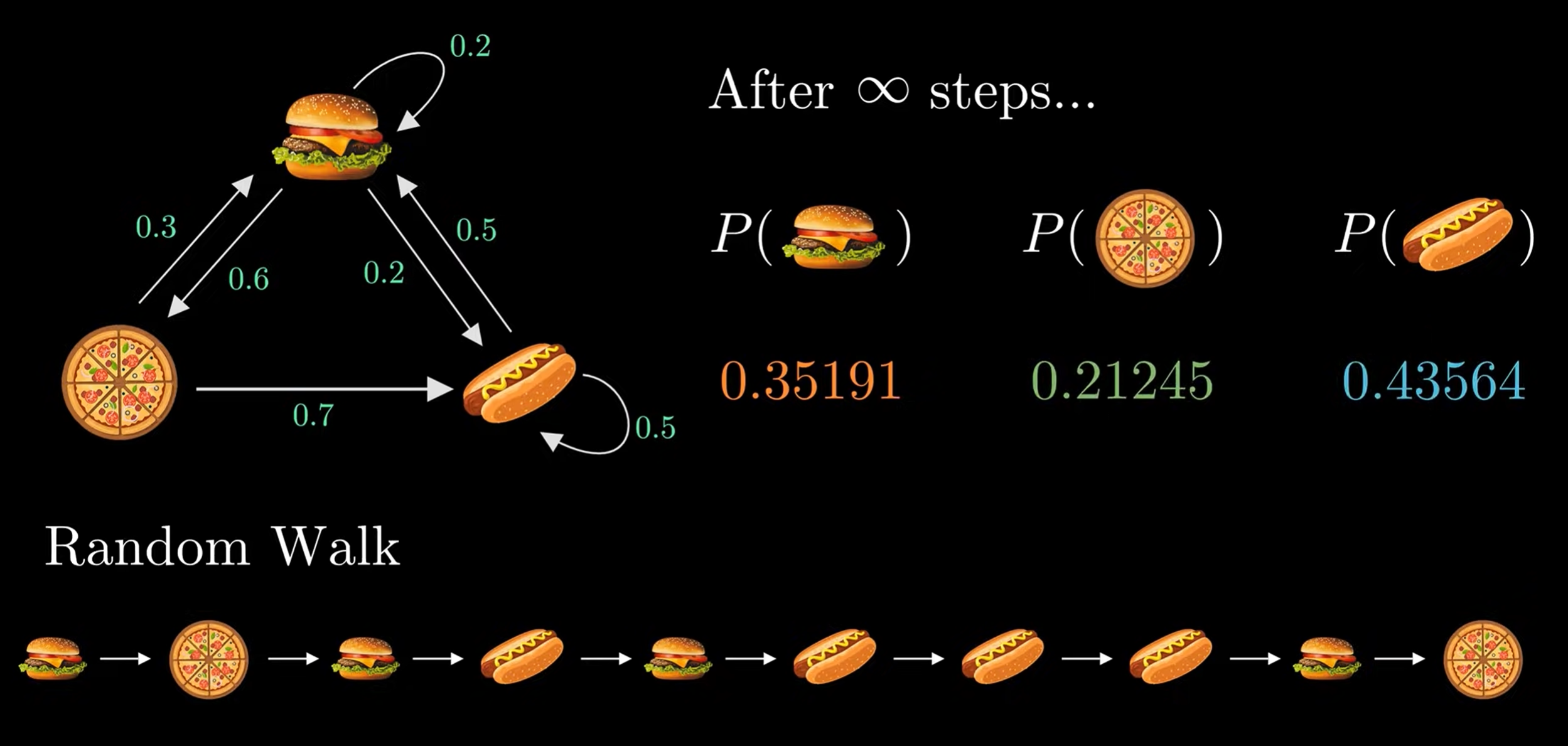
Markov chain
Data Processing Inequality

注意:
:两个圆重叠的部分。 :X 的圆与 Y,Z 联合的圆的交叠面积(整个 区域和 的交集)。 :是三者交叠的中间那一块重叠部分(即三圆交集区域)。
这种叫conditional independent :
未知
已知
Sufficient Statistics

| 步骤 | 含义 |
|---|---|
| Given: | |
| Assume / Check: | 给定 |
| Then: | 我们称 T(X) 是参数 |
① 生成过程(自然的信息流方向)
在统计建模里,样本的生成顺序确实是:
也就是说:
θ 是分布的参数,先确定它;
然后根据
从这个分布中采样出数据 ; 最后我们从样本中计算出一个统计量
。
这就是生成模型的自然方向。
② 充分统计量定义时的条件独立方向
但是,当我们定义“充分统计量”时,我们要求:
X 与 θ 条件独立,给定 T(X)
也就是:
这个条件反过来可以写成一条 Markov 链:
意思是:
一旦我们知道了
Shannon’s Source Coding Theorem

Coding Theorem for DMS

| 特性 | 定长编码 | 变长编码 |
|---|---|---|
| 码字长度 | 全部相同 | 根据符号频率不同而变化 |
| 示例 | A=00, B=01, C=10, D=11 | A=0, B=10, C=110, D=111 |
| 优点 | 编码/解码简单、易同步 | 能根据概率分配更短码,节省平均码长 |
| 缺点 | 不够压缩高效 | 需要设计前缀码、防止歧义 |
| 应用 | 固定块压缩、信道编码 | Huffman 编码、算术编码、自然语言压缩 |
在源编码定理里,n 是“块长”(block length),也就是我们一次拿多少个源符号一起去编码。
现实里,信息源 X 会持续输出很多符号:
比如:
= 第一个字母 = 第二个字母 = 第三个字母
我们可以选择“每次编码 1 个符号”,也可以选择“每次编码 2 个、4 个、1000 个符号”, 这时的“每次编码的符号数量”就是 n。
R 是你允许的“平均码率上限”;
typical set

性质
典型集的这些性质(信息量差不多、概率差不多、总概率≈1)只有当 n 很大时才成立。

编码
