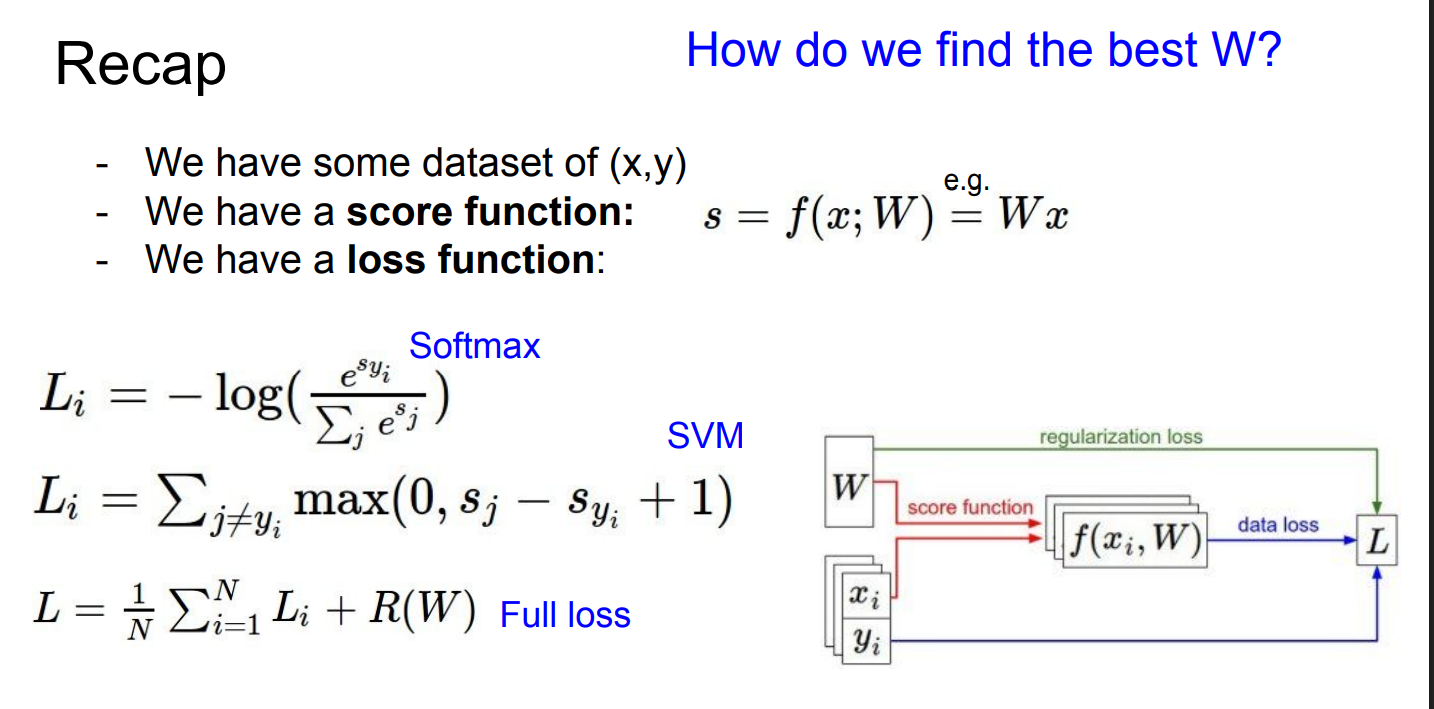
CIFAR-10

分类器输出的是 scores,不是概率
随机初始化的 W 基本是“瞎猜”,所以大多数列都是 bad
训练的目标,就是调整 W,让 正确类别的 score 永远比其他类别高
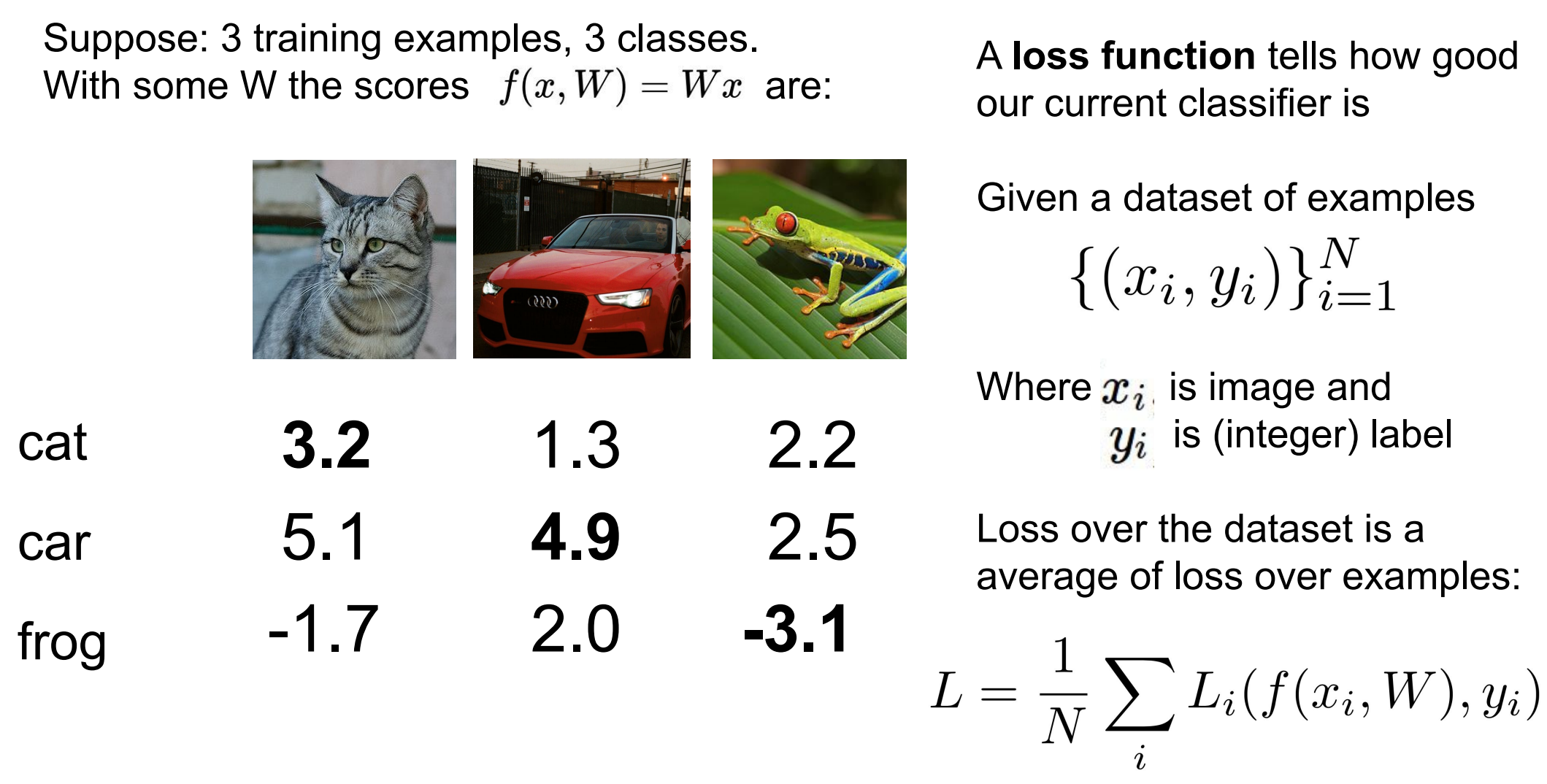
score 只是“打分”,没有好坏尺度
loss 把“预测对错 + 错得多严重”压缩成一个数
数据集 loss = 所有样本 loss 的平均
训练 = 调 W,让 loss 变小
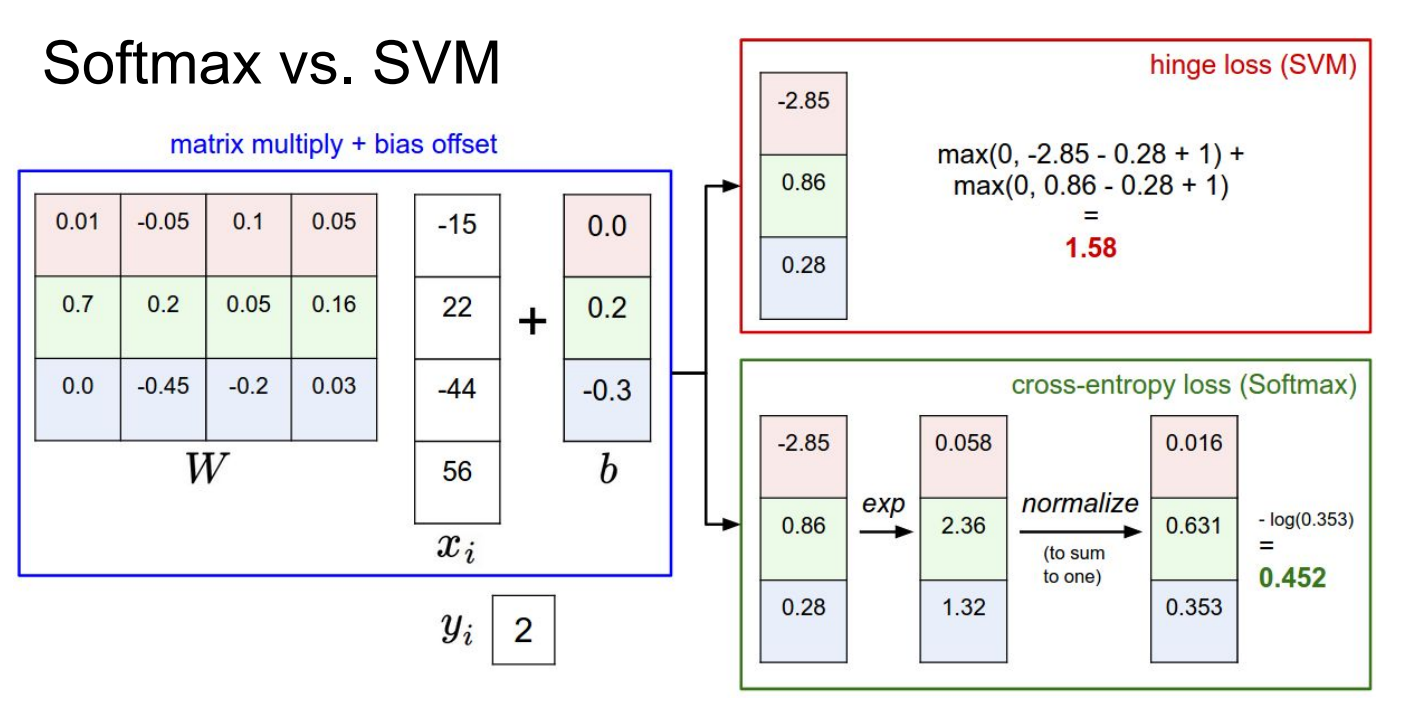
Multiclass SVM loss
深度学习里的 SVM loss ≠ 传统 SVM 模型

对不对(classification)
- 错 → 一定有 loss
错得有多离谱(ranking & margin)
- 错得越多,loss 越大
对得是否“有把握”
- 对了但 margin 不够,也会被罚
看图
情况 1:
正确类别 明显赢了
蓝线在 0 上
loss = 0
不罚,说明模型对这个类别“有把握”
情况 2:
正确类别虽然更大,但 margin 不够
loss 是正的
差得越少,罚得越多
预测对了,但不自信,也要罚
情况 3:
错误类别 ≥ 正确类别
预测错
loss 很大
预测错 + 错得离谱 → 重罚
计算过程



讨论改变

Q1: Car: 4.4
For the cat class:
For the frog class:
Total Loss:
Since both of the incorrect classes (cat and frog) have a loss of 0, the total loss is:
Q2: What is the min/max possible SVM loss
Maximum Loss:
- we want to maximize the difference
for each incorrect class j. This would happen if the correct class score is small (near 0) and the other class scores are large.
Minimum loss:
- we want the score of the correct class
to be sufficiently larger than the other class scores . This would ensure that the margin is positive, and thus the term becomes 0 for all incorrect classes.
Q3: At initialization, W is small, so all
多分类 SVM 的单样本损失是:
第一步:代入初始化条件
所以对任意错误类别
而
第二步:有多少项会被加进去?
一共有 C 个类别
正确类别是 1 个
错误类别是 C−1 个
所以:
全部 N 个样本的总 loss(不取平均):
如果是平均 loss(常见实现):

Q4: 如果求和不排除正确类别
SVM 的思想是:
“正确类别要比错误类别至少大 1”正确类别不应该和自己比较
否则模型会:
永远无法把 loss 降到 0
即使已经完美分类,也会被强制惩罚 1
Q5 :原来每个样本的 loss 是把所有错误类别的 hinge 违约量 相加(sum),那如果改成 取平均(mean) 会怎样。
标准(sum):
改成 mean(对错误类别取平均):
在这张图里 C=3⇒C−1=2,所以 mean 就是把原来的 loss 除以 2。
第 1 个样本:原来
,mean 后 第 2 个样本:原来 L
,mean 后还是 0 第 3 个样本:原来
,mean 后
直观上:mean 不会改变“谁违反了 margin、违反多少”的相对关系,只是把尺度缩小了;训练时等价于把梯度整体缩放了一个常数这里是
Q6 把原来的 hinge loss(一次) 改成 squared hinge loss(二次 hinge):把每个违反间隔的量先算出来,再平方后求和。
原来(一次 hinge):
现在(平方 hinge):
它的含义很直接:
如果某个错误类别没违反间隔
,那一项还是 0; 如果违反了
,原来惩罚是 ,现在变成 ,**大错被惩罚得更重,小错惩罚更温和
Q7: Suppose that we found a W such that L = 0. Is this W unique?
2W 也能导致L=0,不唯一
代码实现

Regularization
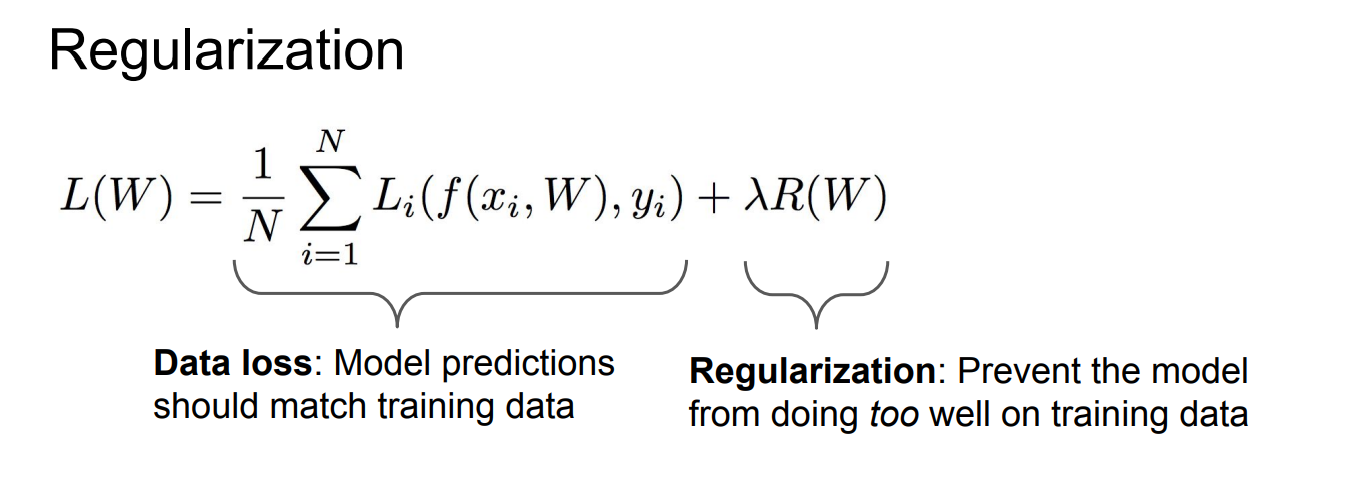
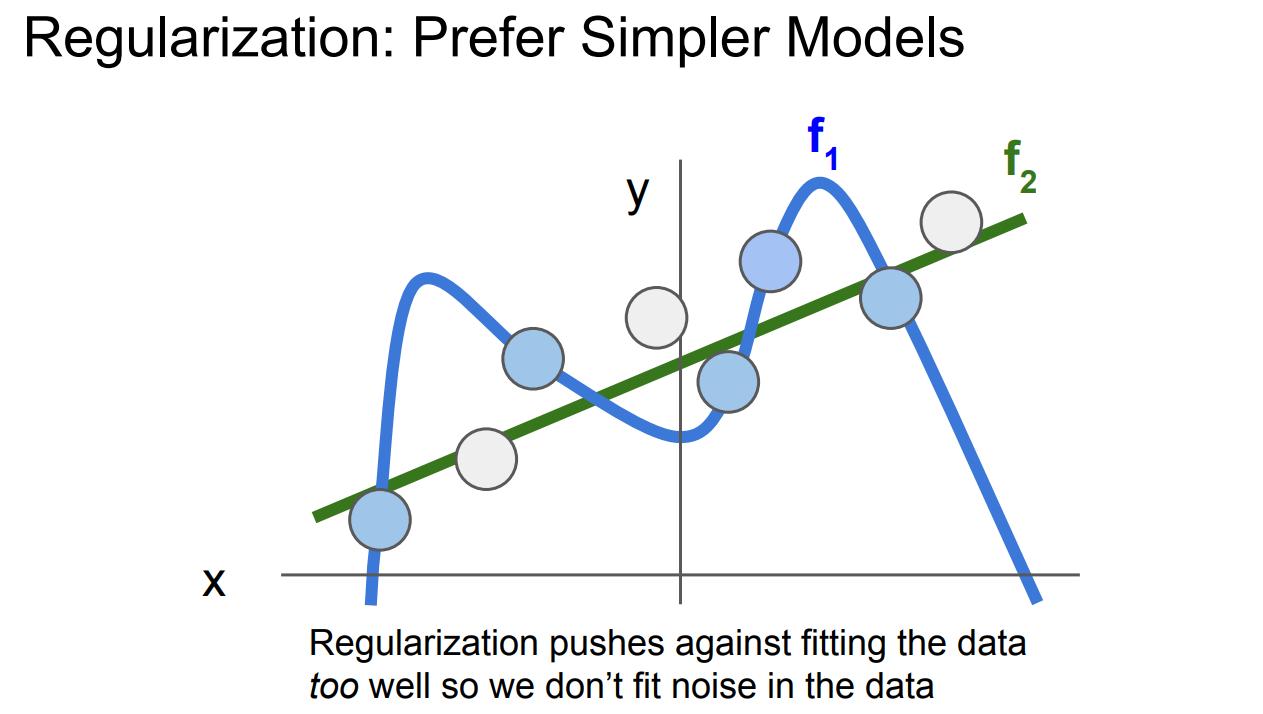
**图中有两个模型 :
是一个过拟合的模型,试图通过曲线精确拟合每个数据点,包括数据中的噪声点(即图中的“白色点”)。这种情况意味着模型复杂,容易将数据中的随机噪声也当作规律来拟合,导致模型对训练数据的适应性很好,但对新数据的泛化能力差。 是一个更简单的模型,它并不精确拟合每一个数据点,而是通过一条平滑的直线尽量简化拟合。这样的模型避免了过度拟合,减少了对数据噪声的敏感性,从而更可能具有更好的泛化能力。
正则化的作用:
正则化通过惩罚复杂的模型,避免它们过度拟合训练数据。这样,模型在优化过程中会倾向于选择更简单的结构,从而避免了对数据中的噪声进行过多拟合
正则化控制了模型的复杂性,使得它更好地捕捉到数据的真实模式,而不是偶然的噪声。

Why regularize?
- Express preferences over weights
- Make the model simple so it works on test data
- Improve optimization by adding curvature
偏好

对 L2 正则化 而言,惩罚的是平方范数,
相反,对 L1 正则化,惩罚的是绝对值之和,
Softmax classifier

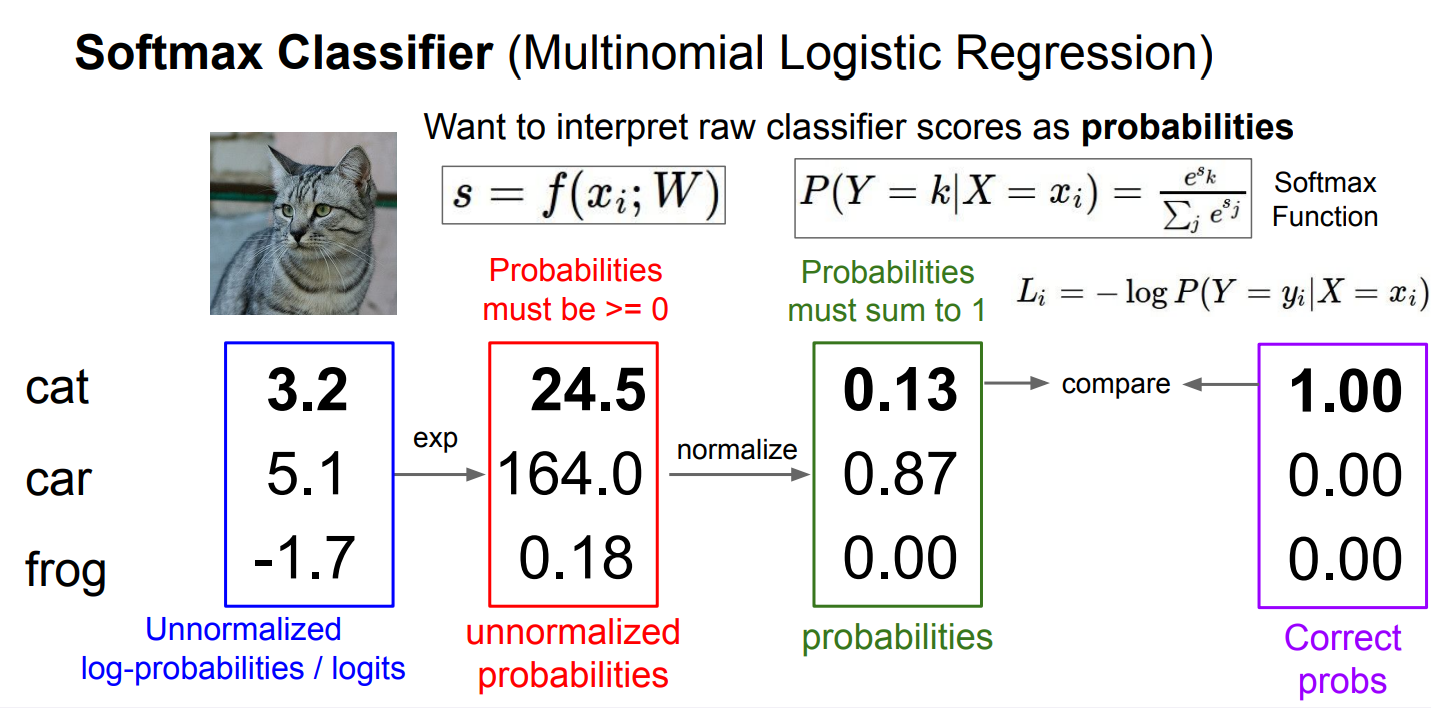
Softmax 分类器把原始打分(logits)一步步变成概率并计算损失 的全过程:
首先模型对输入
接着对每个分数取指数,得到非负的“未归一化概率”
然后做归一化,用每一类的指数值除以它们的总和
这一步保证所有概率之和为 1;
最后如果真实标签是 cat,就取对应概率计算交叉熵损失(
从最大似然角度看,这等价于通过调整权重 (W) 来最大化真实类别在 softmax 概率下出现的可能性。
在训练时我们只关注模型给出的真实类别的预测概率
对于其他类别(如 car 和 frog),我们不会直接计算它们的损失值,而是通过整体损失来优化模型。
因此,损失值
信息论角度


用信息论视角解释 softmax + 交叉熵损失,核心在于:模型输出的概率分布 Q(绿色列)与真实标签对应的“目标分布” P(紫色列,one-hot 向量)之间如何度量差异;紫色的 ([1,0,0]) 表示真实分布 P ——样本真实类别是 cat,因此
上图用 KL 散度 表达这种比较:
下图进一步指出训练时实际使用的是 交叉熵
这也从信息论角度解释了为什么 softmax 分类器只“算真实类别那一项”,以及为什么它既可以被看作最大似然估计,又可以被看作在最小化预测分布与真实分布之间的信息差距。
似然和交叉熵
似然(likelihood) 是“从模型角度看数据有多合理”的概率量。
而交叉熵(cross-entropy) 是“从信息论角度度量两个分布有多不一致”的期望信息量;
在 softmax 分类 + one-hot 标签这个特例下,两者在数值上等价,但概念来源不同。
具体地说,似然关注的是单个样本真实标签在模型分布下出现的概率
训练时我们做极大似然,就是让这个概率尽可能大;
为了方便优化,取负对数得到 (
而交叉熵定义为
当监督学习中真实分布 P 是 one-hot(正确类别概率为 1,其余为 0)时,这个求和只剩下一项,正好变成
因此:统计学语言,这是负对数似然;从信息论语言,这是交叉熵;从直觉上看,它是“模型对真实标签有多意外”的自信息**。区别不在公式,而在视角:似然强调“解释数据”,交叉熵强调“分布不匹配的代价”,
| 学科 | 名字 | 视角 | 数学形式 |
|---|---|---|---|
| 概率统计 | 负对数似然 | 数据是否由模型生成 | |
| 信息论 | 交叉熵 | 分布不匹配的代价 | |
| 信息论 | KL 散度 | 编码冗余 | |
| 机器学习 | loss / loss function | 优化目标 |
问题讨论

Q1: 取值范围
这里把 softmax + 负对数似然损失 写成统一形式
首先,softmax 给出的是真实类别的预测概率
Q2:初始化时大小的直观问题
在随机初始化阶段,各类别打分 s_j 近似相等,softmax 后每一类的概率都接近 1/C(C 为类别数),于是单样本的初始损失为
这也是训练开始时常见的 loss 量级来源:比如 CIFAR-10(C=10)初始 loss 约为
两种loss比较

Q1.多分类 SVM(hinge)loss
其中真实类别
第一组 ([10,-2,3]),真实分数是 10,两个错误类的 margin 分别为 (-2-10+1=-11) 和 (3-10+1=-6),都小于 0,因此两项都为 0,整体 SVM loss 为 0;
第二组 ([10,9,9]),真实分数仍是 10,两个错误类的 margin 为 (9-10+1=0) 和 (9-10+1=0),(\max(0,0)=0),因此 loss 仍为 0,说明“刚好满足 margin 要求也不罚”;
第三组 ([10,-100,-100]),两个错误类的 margin 为 (-100-10+1=-109) 和 (-100-10+1=-109),同样都为 0,loss 还是 0。这个例子清楚地体现了 SVM loss 的特性:
只要正确类别比分错误类别至少大 1(margin),就完全不再关心分数有多大,这与 softmax loss“概率越接近 1 越好、永远有梯度”的行为形成鲜明对比。
Q2:Is the Softmax loss zero for any of them?
结论先给出:这三组里,Softmax loss 对任何一组都不可能是 0。
先说 Softmax loss 什么时候等于 0(理论条件)
Softmax loss(对单样本)是
要让
而这等价于:
严格说:
只有当
时,Softmax loss 才能趋近 0 在任何有限分数下,Softmax loss 都 > 0
Softmax loss 的 0 只是“极限值”,不是可达值
对你给的三组 scores 逐一判断
真实类别:
第一组:([10,,-2,,3])
Softmax 概率:
第二组:([10,,9,,9])
第三组:([10,,-100,,-100])
这是最“极端”的一组: