random search


这页在讲最原始、也最低效的一种“训练模型”的办法:随机搜索(random search),本质上是在用纯暴力试错来最小化损失函数。
假设你已经有训练数据 bestloss 初始化为无穷大,然后重复很多次(这里是 1000 次):每一次都 随机生成一组模型参数 W(例如线性分类器的权重矩阵),用这组参数在整个训练集上计算一次损失;如果这次的损失比历史最小值还小,就把这组参数保存下来。循环过程中不断打印“第几次尝试、当前损失、目前为止最好的损失”。最终得到的 bestW 只是 1000 次随机采样中表现“相对没那么差”的那一组参数。
结果大约是 15.5%,为什么幻灯片会说 “not bad”?因为这是一个 10 类问题,纯随机猜测的期望准确率只有 10%,而这个模型虽然是“瞎搜参数”,但已经学到了一点点数据分布的弱结构;不过和 SOTA(≈99.7%)相比,这个差距正好用来强调一个核心结论:不是线性模型不行,而是用“随机搜索”这种不利用梯度信息的优化方法,在高维参数空间里几乎必败.
SOTA
SOTA 是 State Of The Art 的缩写,意思是:当前公认的最好水平 / 最先进的结果。
在机器学习语境里,SOTA 通常指在某个固定数据集 + 固定评测指标下,目前文献或业界能做到的最高性能,比如最高 accuracy、最低 error、最好 F1 等。你这张图里的 “SOTA is ~99.7%” 的意思是:在这个任务(典型是 CIFAR-10 图像分类)上,用当下最强的模型和训练方法,测试集准确率已经能做到大约 99.7%。
理解 SOTA 时有几个关键点:第一,它是相对某个任务和评测协议而言的,不是抽象的“最强模型”;第二,它通常来自复杂模型 + 大量工程与训练技巧(如深层 CNN、数据增强、正则化、预训练等),而不是课堂里演示的线性分类器;第三,SOTA 会随时间变化,是一个动态标杆,今天的 SOTA 明天可能就被刷新。
Follow the slope

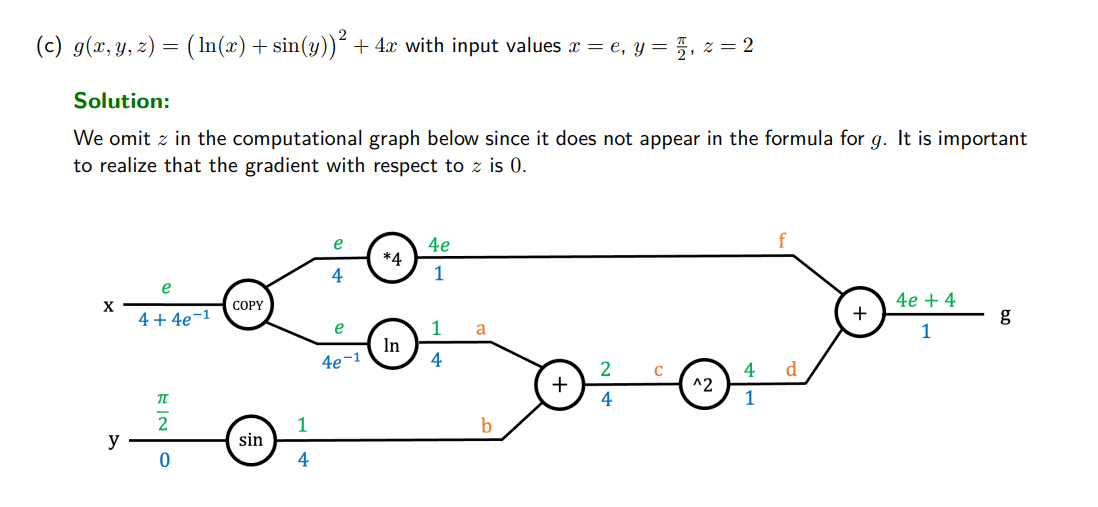
左边把 W 写成一长串数字,是把整个矩阵 flatten 成了一个向量
这是对其中一个

用数值方法近似计算损失函数对参数 (W) 的梯度(numerical gradient / finite difference),也就是在回答一个核心问题:“如果我把某一个权重稍微往上挪一点点,loss 会怎么变?”
具体逻辑是这样的:左边是当前参数向量 W,在它下面算出了当前损失 L(W)=1.25347;中间只对 第一个维度 做一个极小扰动
来近似这个偏导数;在图里的数值下,这个结果是一个负数,表示把
右边那一列的问号,意思是:对 W 的每一个分量都重复同样的操作——一次只 perturb 一个维度,算一次 loss 差分,最后拼起来就得到整个梯度向量
第一个维度改变

第二个维度改变

第三个维度改变

微积分


梯度下降法

在标准的热力图中,红色代表高loss,梯度下降确实是朝着红色的反方向(蓝色方向)前进,以最小化损失函数。
横轴是
SGD

after neural networks then introduce how to update W
neural networks

| 视角 | 本质限制 |
|---|---|
| 视觉角度 | 每类只能学一个“平均模板” |
| 几何角度 | 只能用一个超平面做分割 |
pixel Features

线性分类器 = 像素向量 × 权重矩阵 → 类别分数,本质上是在做‘像素模板匹配’,表达能力极其有限。
image feature
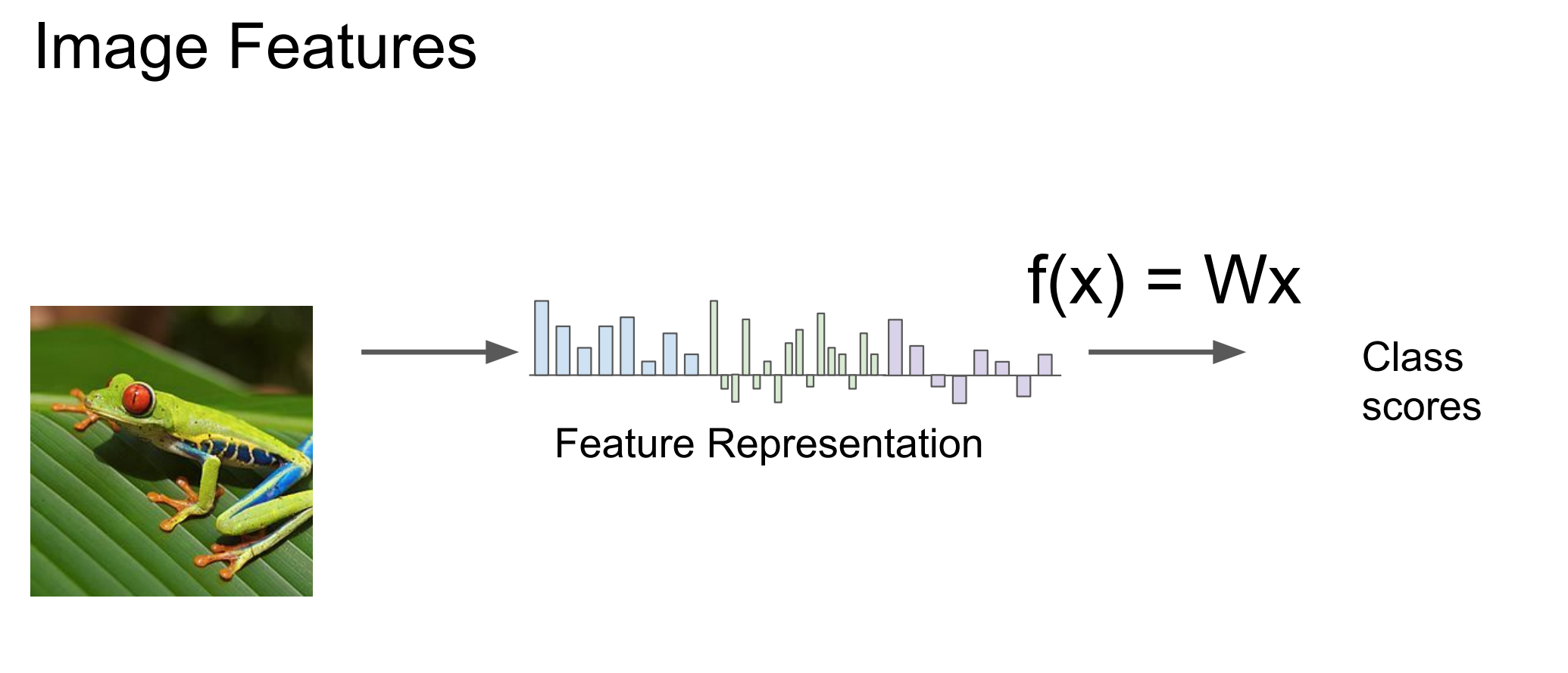
| Pixel Features | Image Features |
|---|---|
| (x) = 原始像素 | (x) = 高级特征 |
| 模型要从像素里“硬学语义” | 语义已经被编码进特征 |
| 每类只能学一个模糊模板 | 线性组合多个语义特征 |
| 很难线性可分 | 可能线性可分 |

color histogram
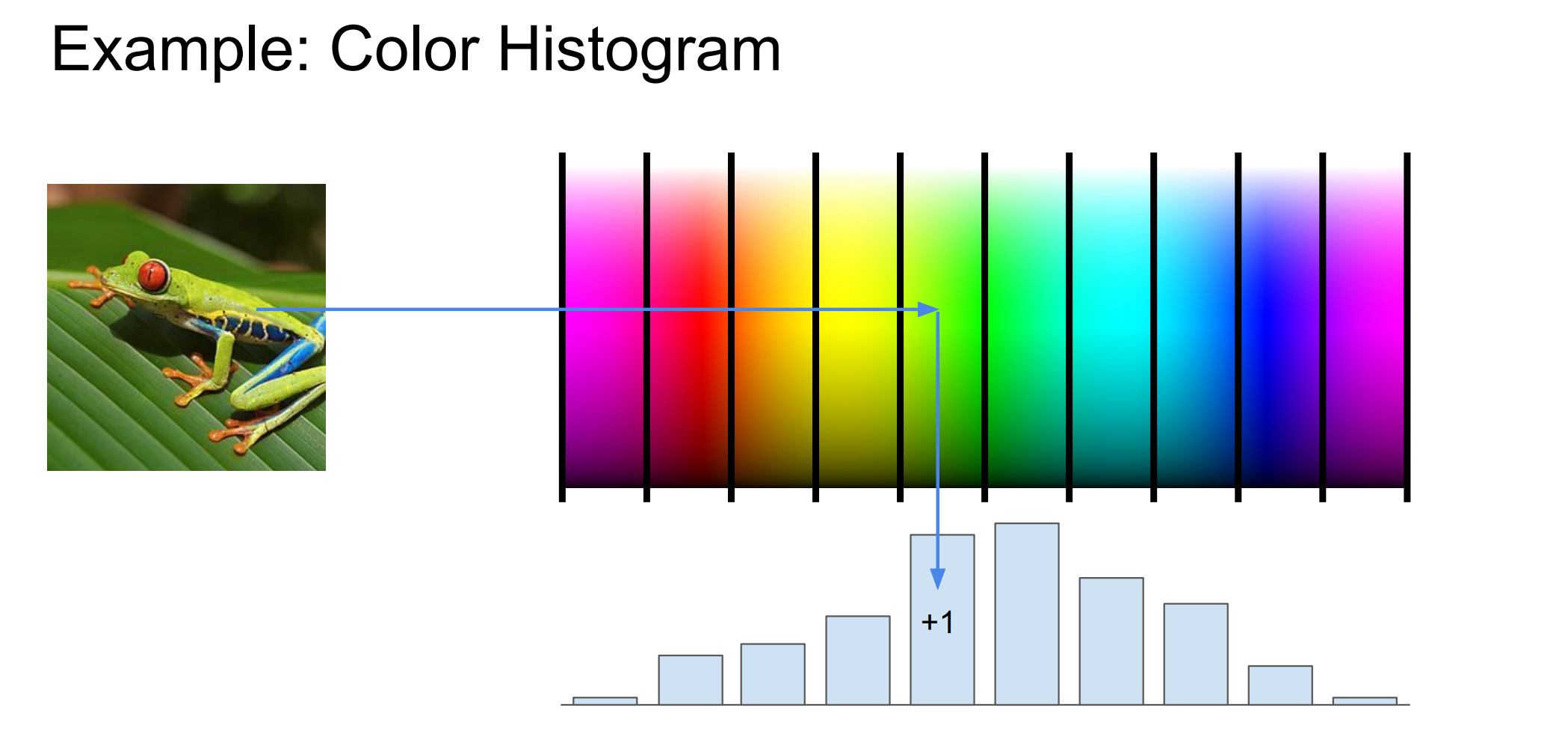
这张图是在举一个非常具体、非常经典的“图像特征工程”例子:颜色直方图(Color Histogram),用来说明“如何把一张复杂图像,变成一个更适合线性分类器的特征向量”。
左边是一张青蛙的图片。
如果你直接用像素做特征,模型看到的是几十万个 RGB 数字,既高维又杂乱。
中间:颜色空间被“分桶(binning)
中间那条彩色带代表颜色空间(可以理解为 Hue / RGB / HSV 中的某一维,图里用的是示意)。
颜色被离散化成一段一段的区间(bins)
黑色竖线就是每个 bin 的边界
箭头 “+1” 含义是:
遍历图像里的每一个像素,看它的颜色落在哪个 bin 里,然后给对应的 bin 计数 +1
底部:得到一个直方图(feature vector)
你得到的是:
这张图在说明:颜色直方图通过“统计像素颜色分布”,把一张图像压缩成一个固定长度的特征向量,使线性分类器能更容易工作,但代价是丢失空间与形状信息。
Histogram of Oriented Gradients

这张图是在系统性地说明 HoG(Histogram of Oriented Gradients,方向梯度直方图)是怎么把一张图像变成“有形状语义的特征向量”的。
HoG (算法流程)
先算梯度(边缘)
对原始图像(通常是灰度):
用
(如 Sobel)算每个像素的梯度 得到:
梯度幅值(边缘强不强)
梯度方向(边缘朝哪个方向)
右边那张黑底白纹的图,本质上就是:
哪儿有强边缘、边缘朝哪儿
把图像分块(spatial bins)
图里写得很清楚:
把图像切成 8×8 像素的小区域(cells)
左图红框就是在标一个 cell
这是为了保留局部结构信息:
青蛙的腿、叶脉、轮廓
而不是全局一锅端(和 color histogram 的最大区别)
把所有 cell 的直方图拼起来
右下角的计算在说明维度从哪来:
320×240 图像
每个 cell 是 8×8
所以:
横向:(320/8 = 40)
纵向:(240/8 = 30)
每个 cell 有 9 个数
单看每个cell每个小块里做“方向直方图”
在一个 8×8 的 cell 里:
把梯度方向 量化成 9 个方向 bin(比如 0°–180° 分 9 段)
每个像素:
看梯度方向落在哪个 bin
用梯度幅值给对应 bin 投票
结果是:
这个小区域里,“哪种方向的边缘最多”
最终特征维度:
得到一个 10,800 维的特征向量
HoG 在“表达什么信息”
HoG 不是在看颜色,而是在编码:
局部边缘方向分布
形状轮廓
物体姿态
比如:
青蛙腿是斜线
叶脉是平行线
轮廓有明显方向模式
这些在 HoG 特征里是稳定可捕捉的。
HoG 比 Color Histogram 强在哪?
| 特征 | Color Histogram | HoG |
|---|---|---|
| 是否看颜色 | ✅ | ❌ |
| 是否看形状 | ❌ | ✅ |
| 是否保留空间结构 | ❌ | ✅(局部) |
| 对光照变化 | 一般 | 较鲁棒 |
| 可线性分类 | 有限 | 很强 |
Bag of words
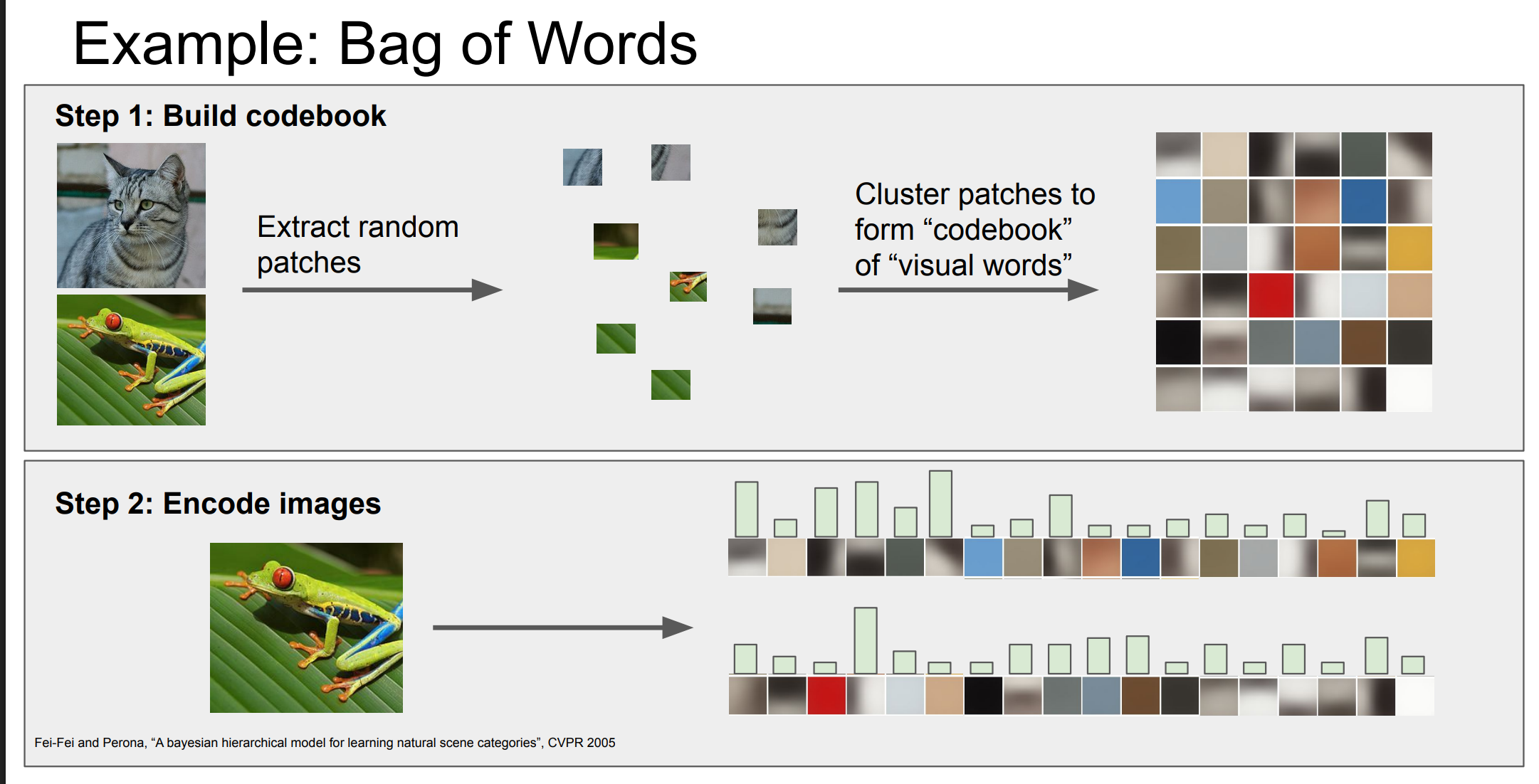
Bag of Words 把一张图像看成“很多局部小块的集合”,先学一套“视觉单词”,再统计这些单词在图像里出现的频率,用这个直方图做分类。
Step 1:Build codebook(建立“视觉词典”)
从大量图像中随机抽小 patch
左上角两张图(猫、青蛙)只是例子,真实情况是:
从整个训练集
在随机位置
抽取很多 小 patch(比如 8×8 / 16×16)
每个 patch 是一个“局部视觉模式”
把这些 patch 聚类(Clustering)
接下来这一步非常关键:
把所有 patch 的特征(像素 / HoG / SIFT)拿出来
用 k-means 聚类
得到 (K) 个聚类中心
这些中心就叫:
visual words(视觉单词)
右上角那一堆小方块:
每一个 ≈ 一个“典型局部外观”
就像 NLP 里的 “cat / dog / tree”
这整个集合叫 codebook / visual vocabulary。
Step 2:Encode images(把图像编码成直方图)
对这张图像:
再次抽很多小 patch
对每个 patch:
找它最像哪个 visual word
相当于“给 patch 贴一个单词标签”
统计“词频” → 直方图
现在你做的事情和 NLP 里的 BoW 完全一样:
第 1 个 visual word 出现了多少次?
第 2 个出现了多少次?
…
第 K 个出现了多少次?
于是你得到一个向量:
这就是:
一张图像的 Bag of Visual Words 表示
右下角那一根根柱子,就是这个 词频直方图。
和你前面学的 Color Histogram / HoG 的关系
| 方法 | 在统计什么 | 是否保留空间 |
|---|---|---|
| Color Histogram | 颜色分布 | ❌ |
| HoG | 局部边缘方向 | ✅(弱) |
| BoW | 局部外观模式 | ❌(默认) |
BoW 的关键特点是:
完全丢掉“patch 在哪里”,只关心“出现过什么”
这就是“Bag”的含义。
为什么当年 BoW 很强?
因为它第一次做到:
不用全图模板
用局部模式的组合
表达复杂物体(猫 = 耳朵 + 毛 + 眼睛 + 轮廓)
而且:
特征是固定长度
非常适合 Linear SVM
但它也有致命缺点
❌ 完全不看空间关系
- 眼睛在头上还是在脚下,一样算
❌ codebook 是人为设的(k-means)
❌ pipeline 很碎(patch → feature → cluster → encode)
设计特征与拼接
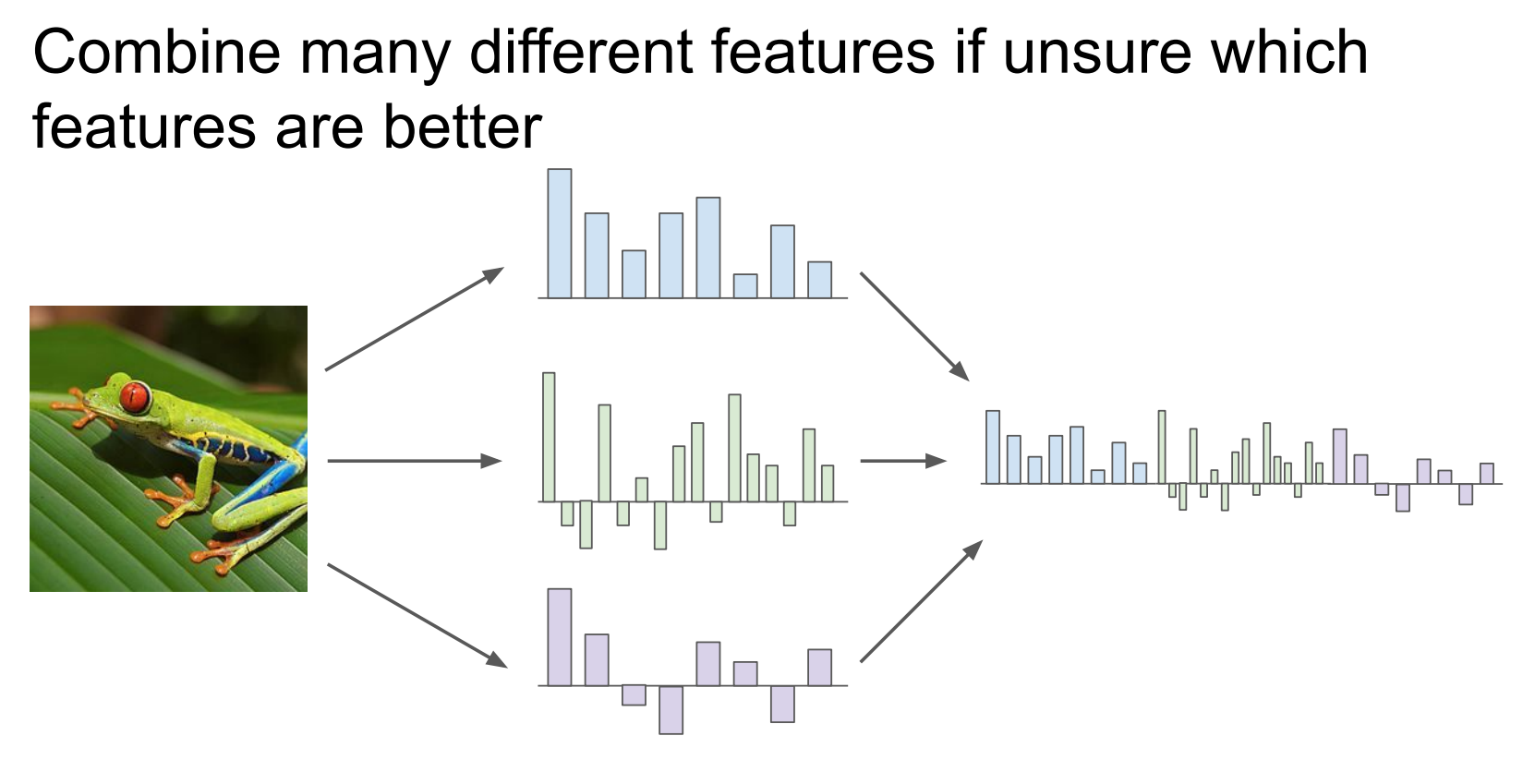
如果你不知道哪种手工特征最好,就把多种特征全部拼起来,让分类器自己学权重。
对同一张图,你可以提取多种完全不同的特征:
蓝色直方图:
比如 颜色直方图(Color Histogram)绿色直方图:
比如 HOG(边缘/形状)紫色直方图:
比如 纹理、SIFT、LBP 等
每一种特征都在回答不同问题:
| 特征 | 擅长什么 |
|---|---|
| 颜色 | 全局外观 |
| HOG | 轮廓 / 形状 |
| 纹理 | 表面结构 |
右边:特征拼接(concatenate)
也就是:
不是“选一个”
而是全部拼在一起
这是传统 CV 的最高级玩法:
人类负责设计特征,模型只负责学“怎么用这些特征”
特征这件事,其实可以不用人管
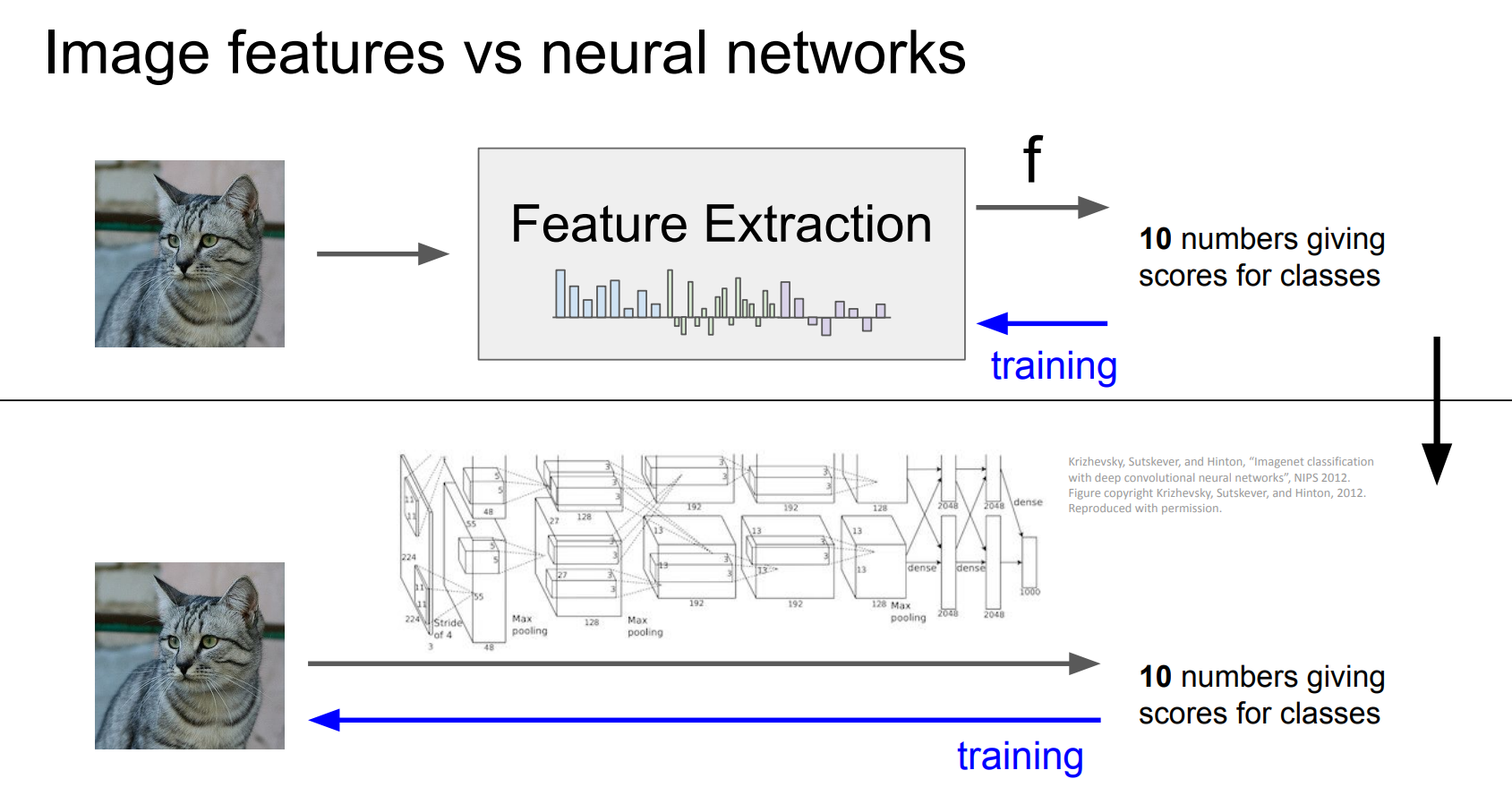
上半部分:传统 pipeline(手工特征时代)
1 | Image |
关键点在这两点:
Feature Extraction 是人设计的
HOG 怎么算?
bin 怎么分?
patch 多大?
训练只能更新最后的分类器
蓝色箭头只指向分类器
特征是“固定的”
模型无法告诉你:这个特征好不好
下半部分:神经网络(端到端学习)
1 | Image |
但关键变化在训练方向:
蓝色箭头一路反传到输入
特征本身也是被训练出来的
本质区别一句话总结
| 传统方法 | 神经网络 |
|---|---|
| 特征靠人 | 特征靠学 |
| 特征固定 | 特征可学习 |
| 模型浅 | 表示逐层抽象 |
| 上限受限 | 表示能力极强 |
multi-layer perceptrons

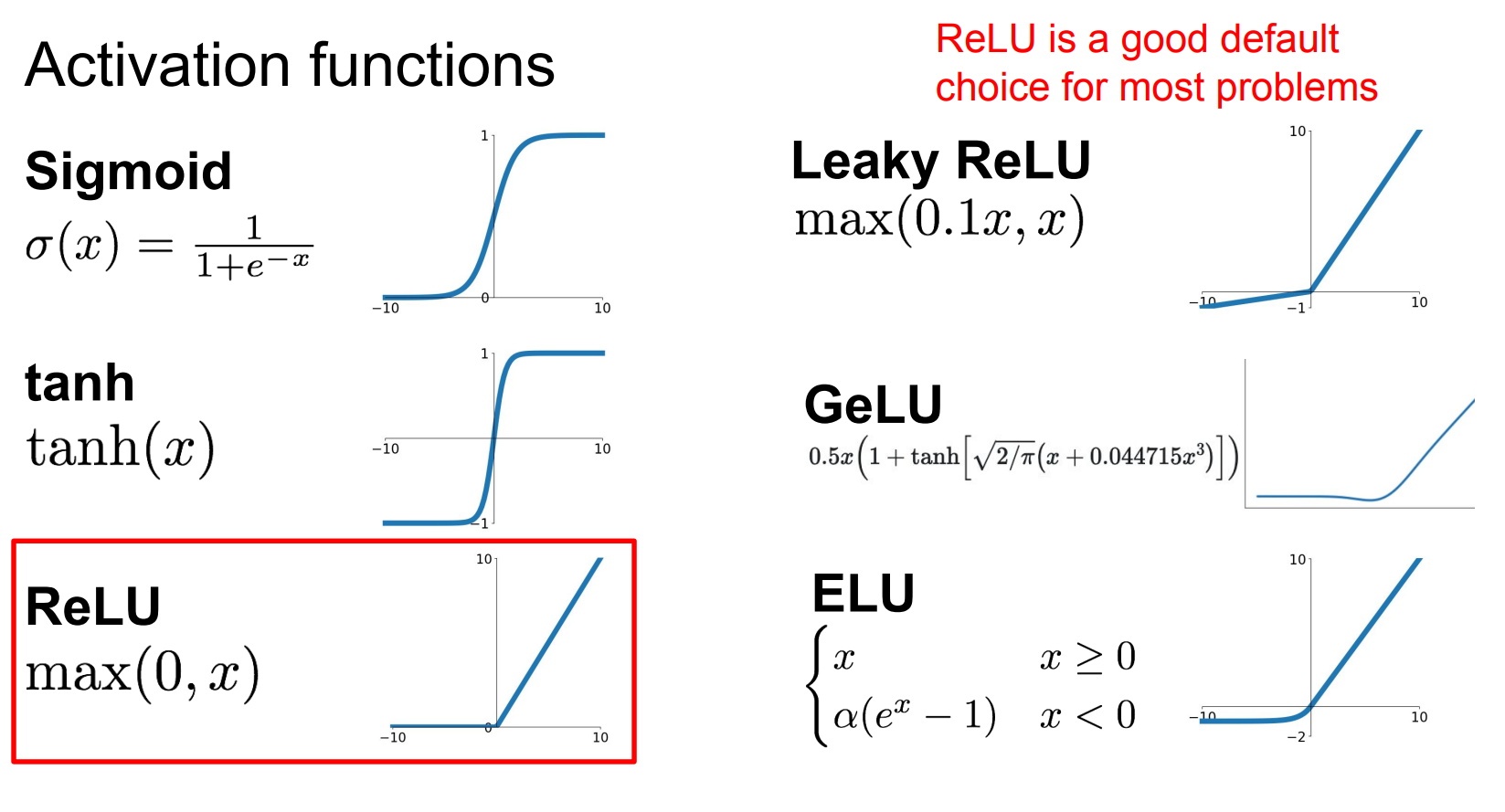
activation function


Architectures
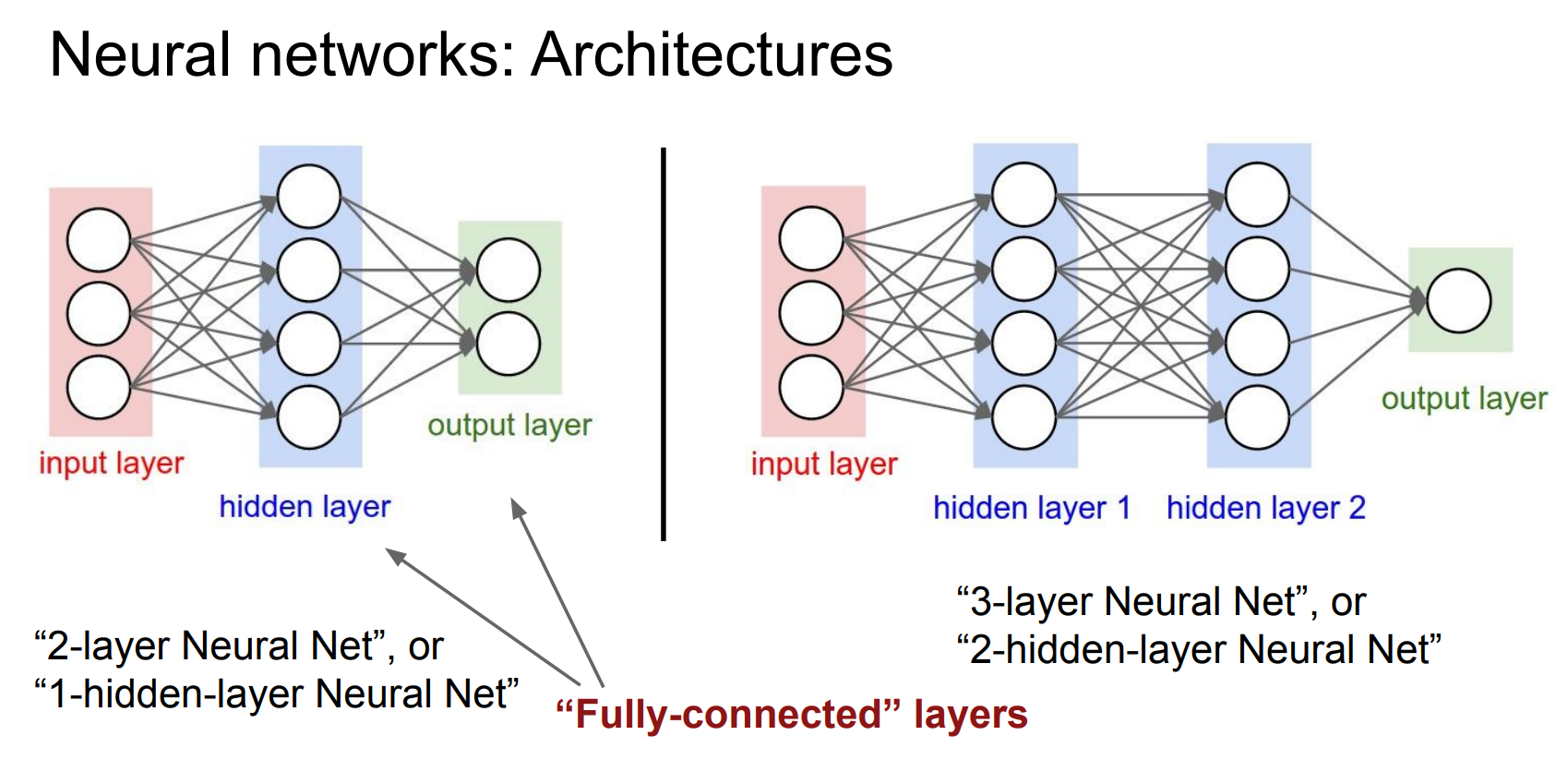
“层数 = 含参数的层(有权重矩阵的层)”
也就是说:
✅ 算: fully-connected / convolution / linear 层
❌ 不算: input layer(只有数据,没有参数)
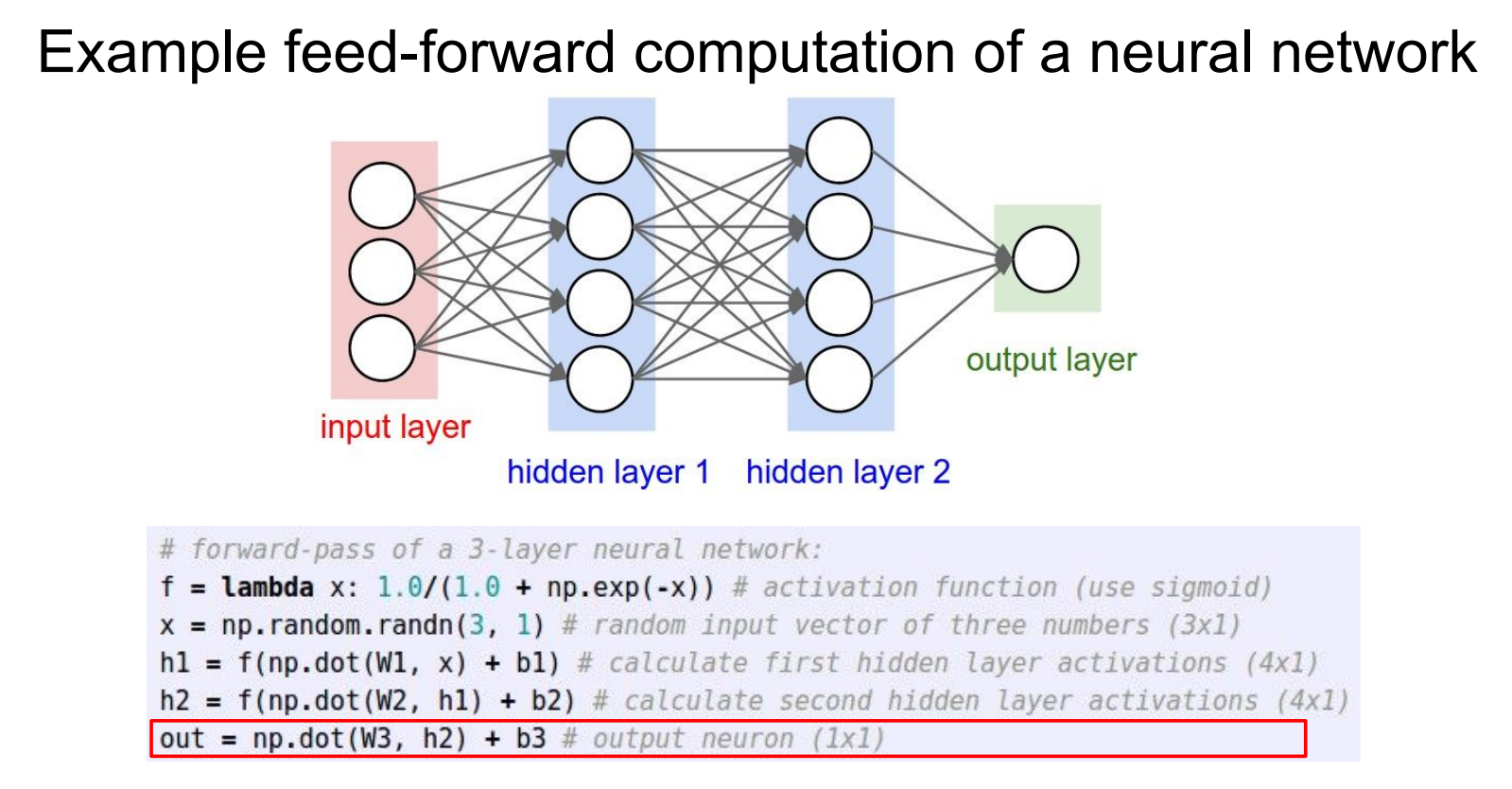
network代码

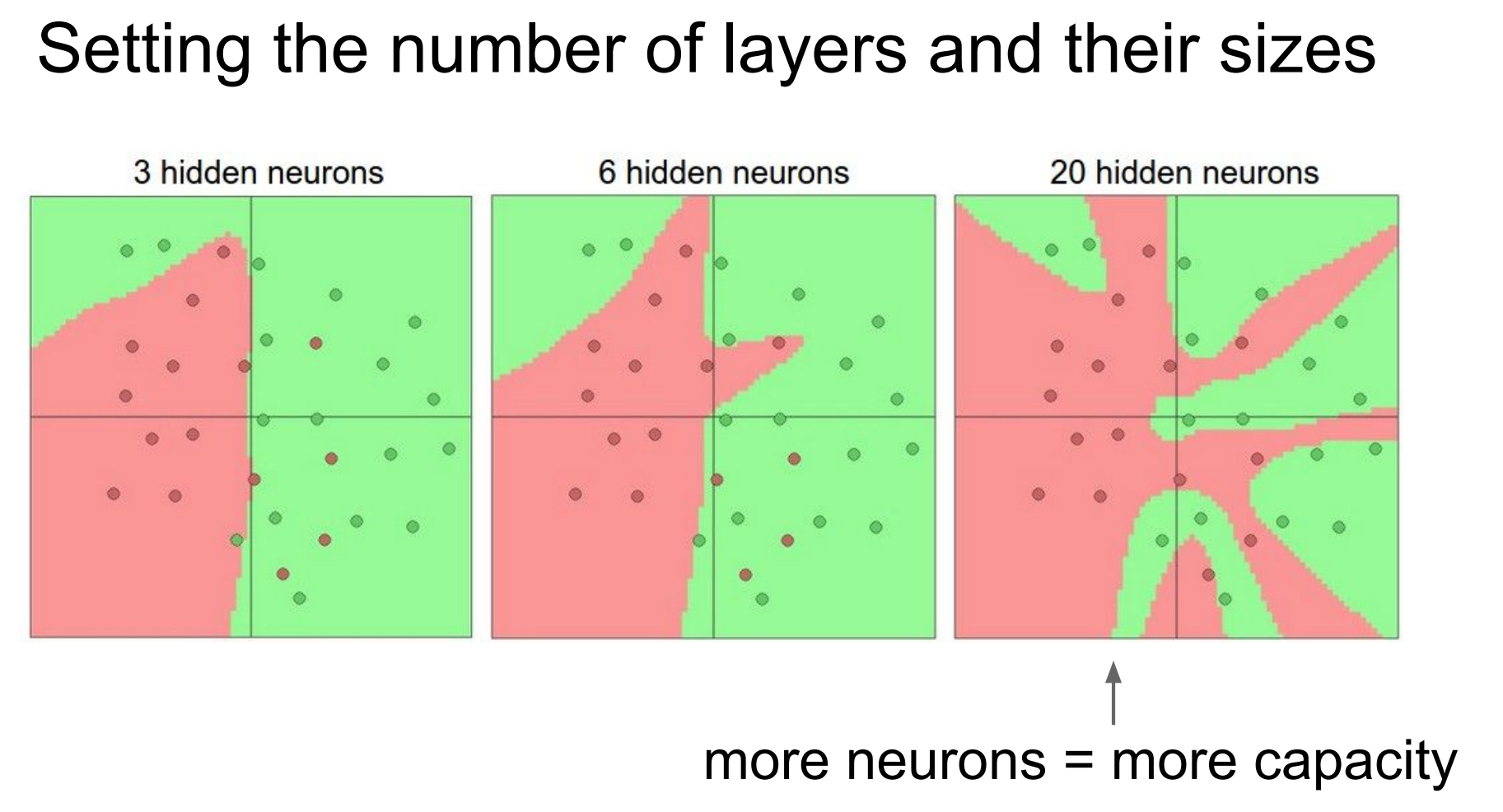
layer
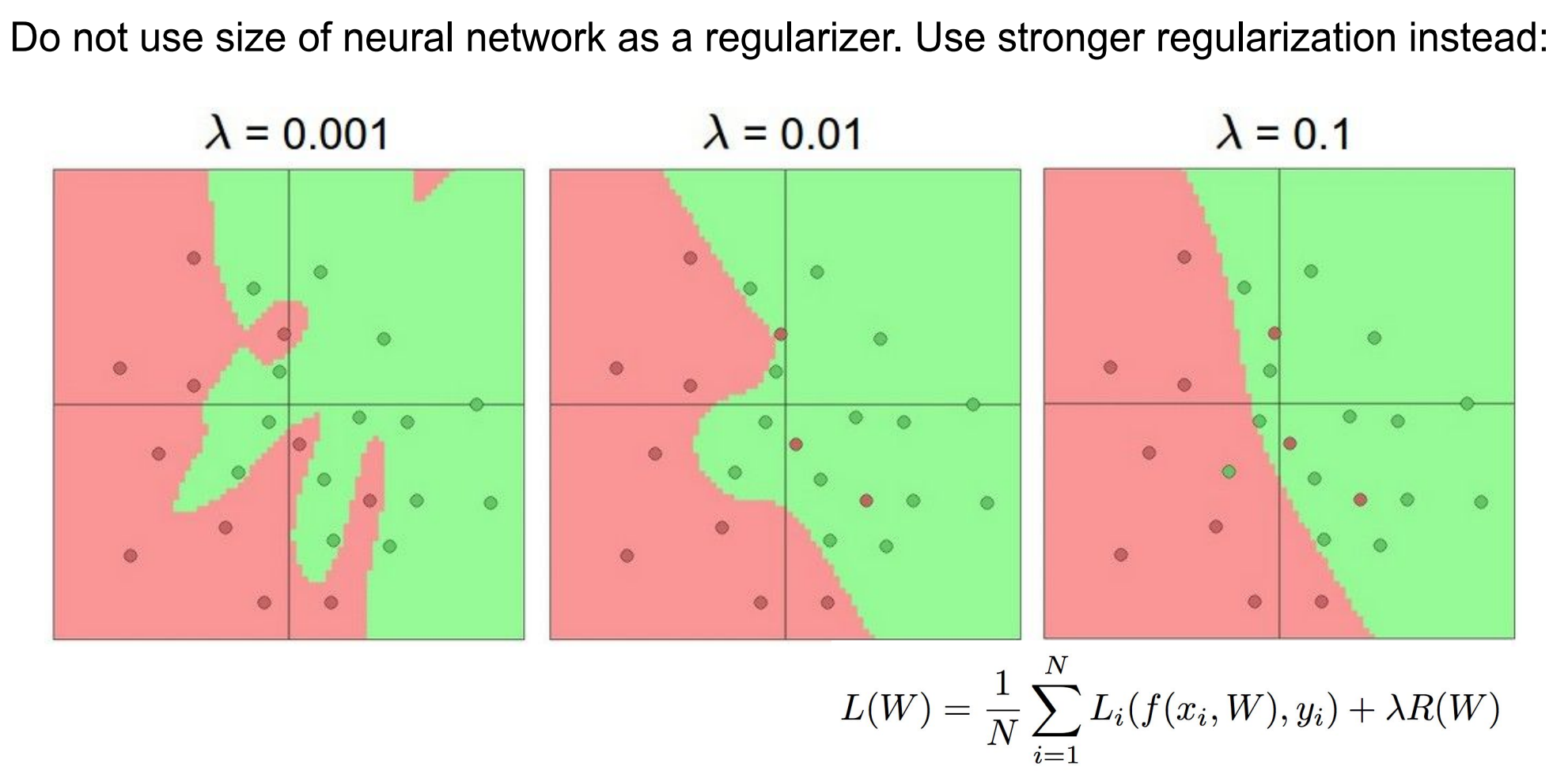
regularizer
如何计算梯度


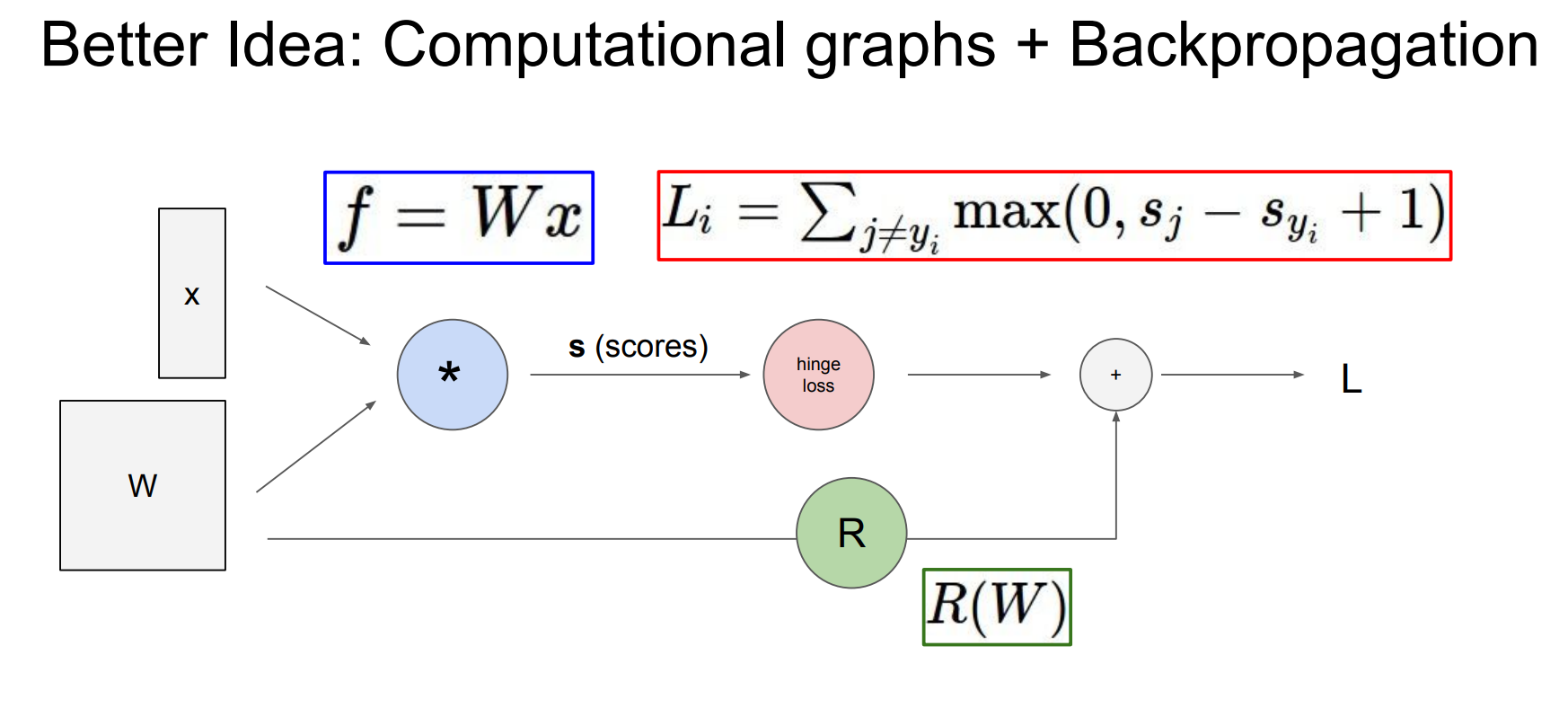
Backpropagation
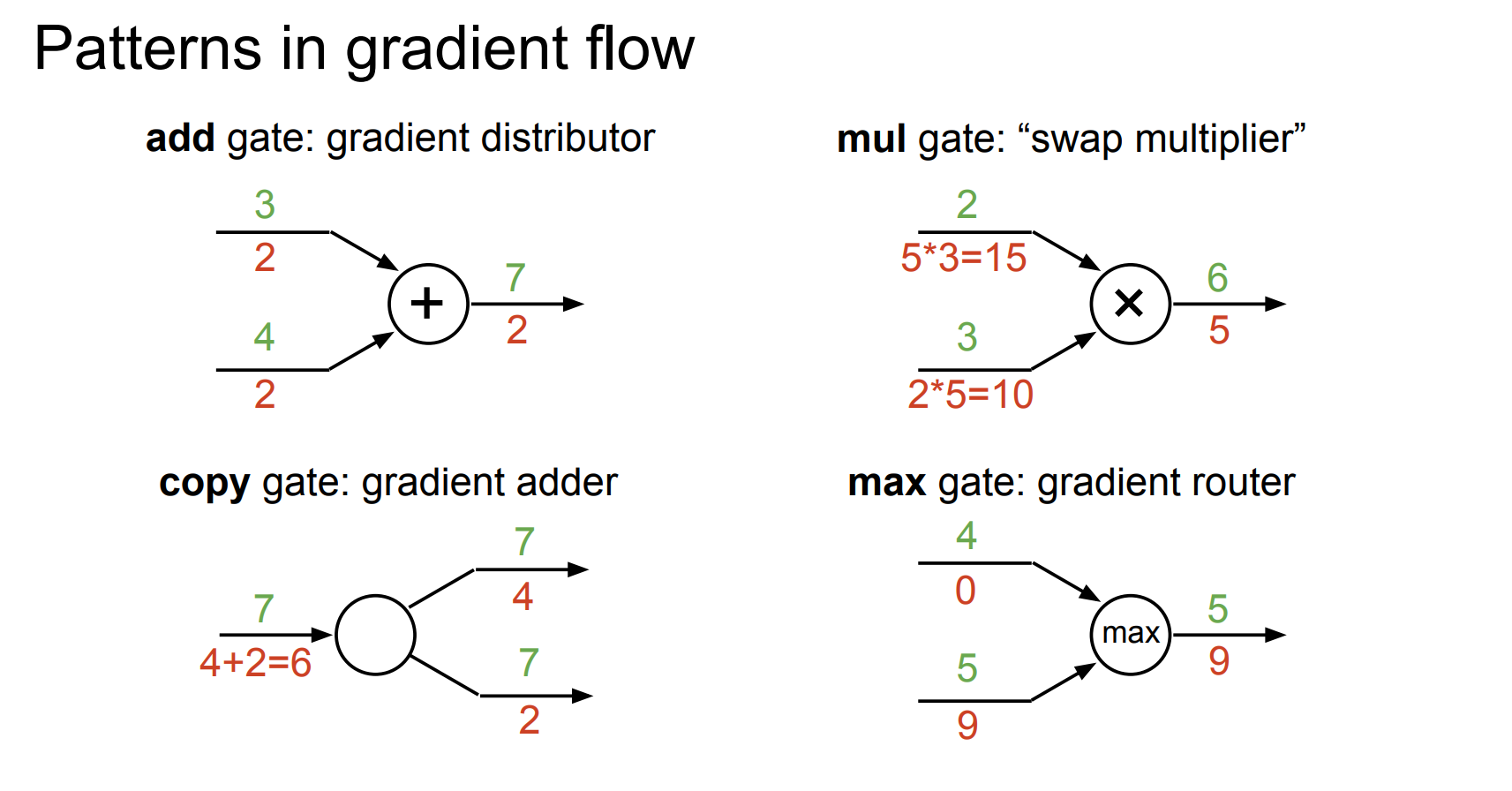
加法和乘法
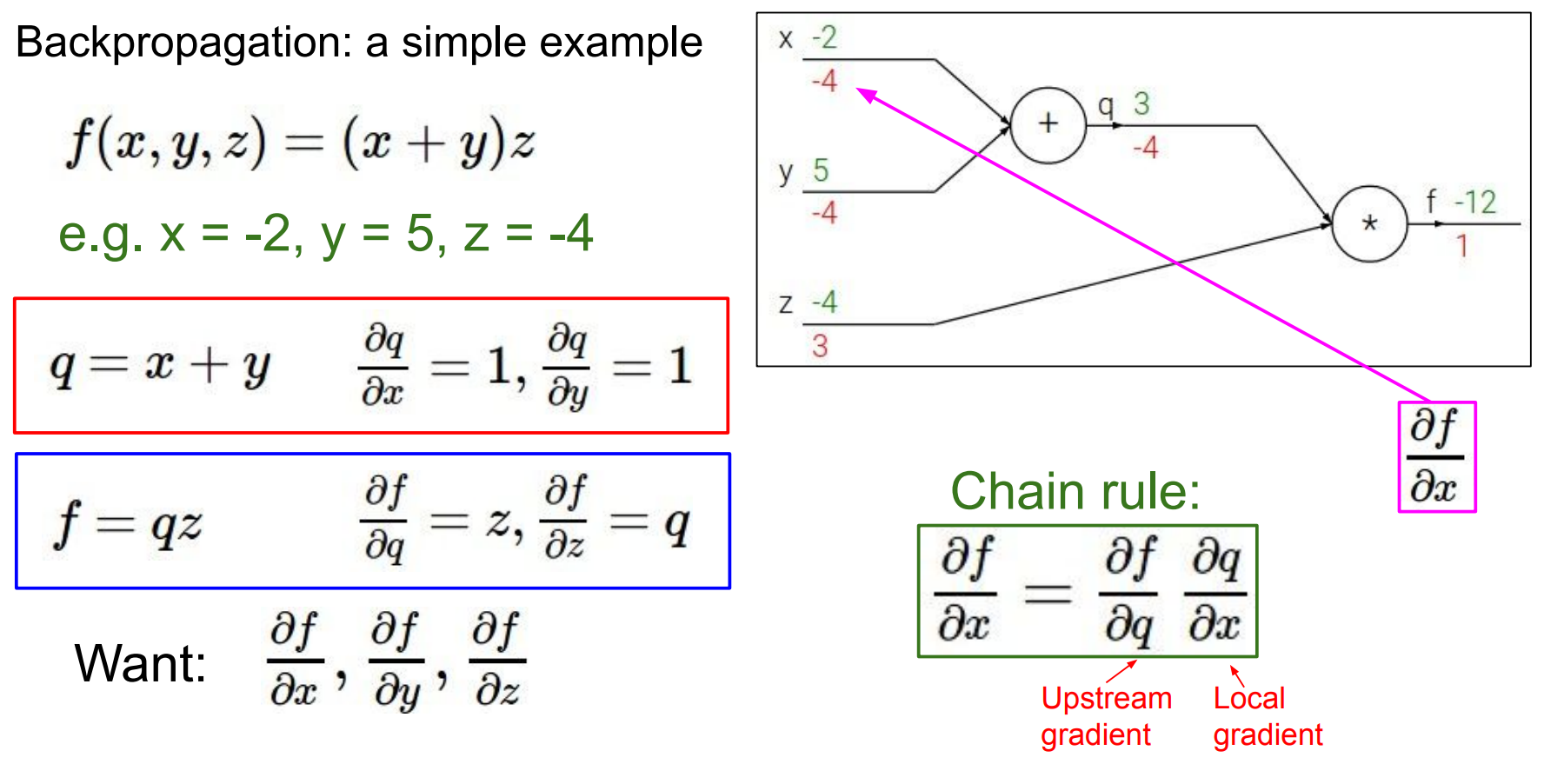
把复杂函数拆成若干局部算子,先前向算数值,再用链式法则从输出往回传梯度。这里的函数是
反向传播时不再整体对 f 求偏导,而是分两层:局部梯度方面,加法节点满足
图中“upstream gradient”指从后面节点传回来的
反向传播的核心规则就是每条边上传递的梯度 = 上游梯度 × 局部梯度。、
local gradient
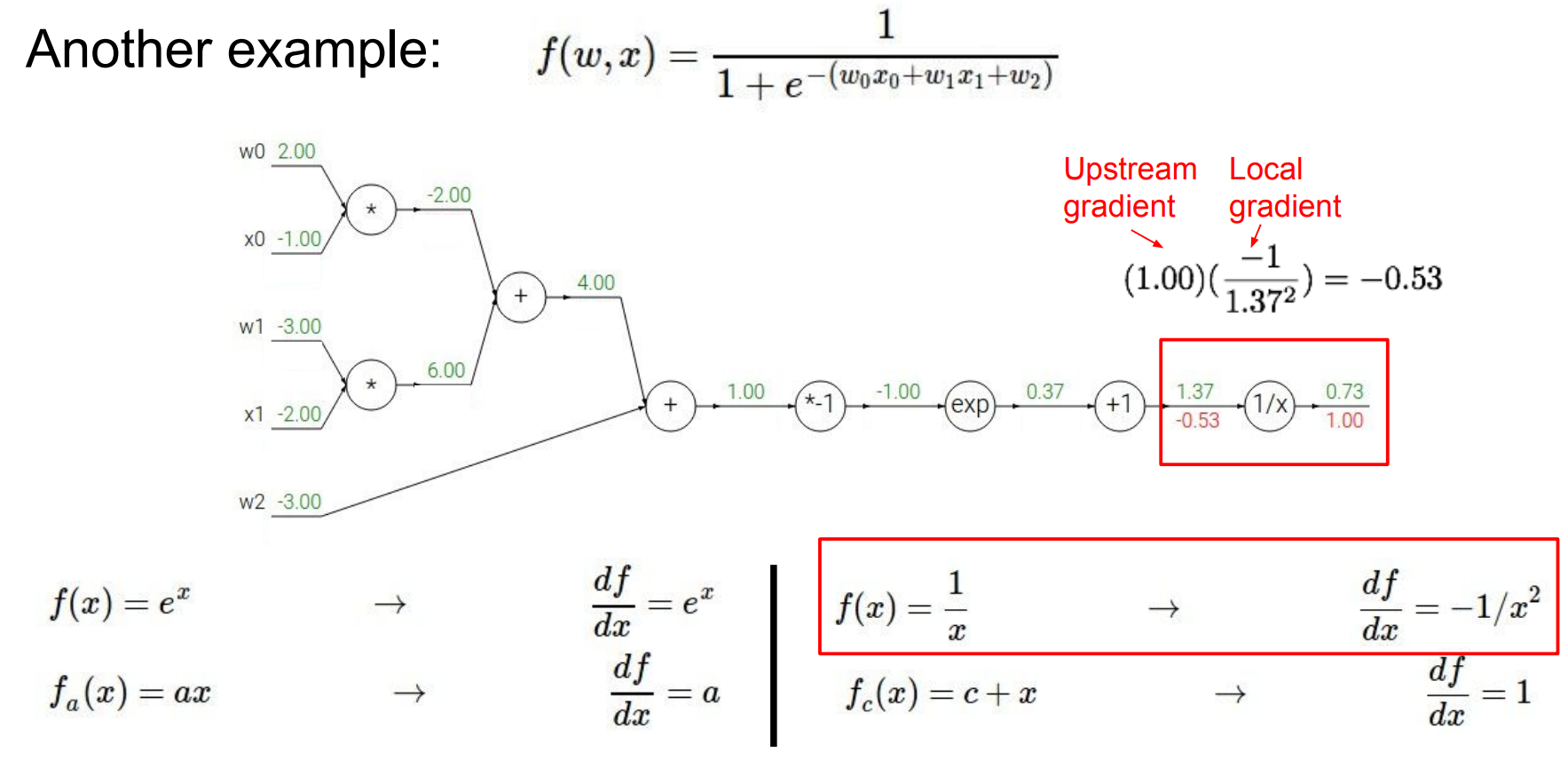
local gradient :输入的值带入导函数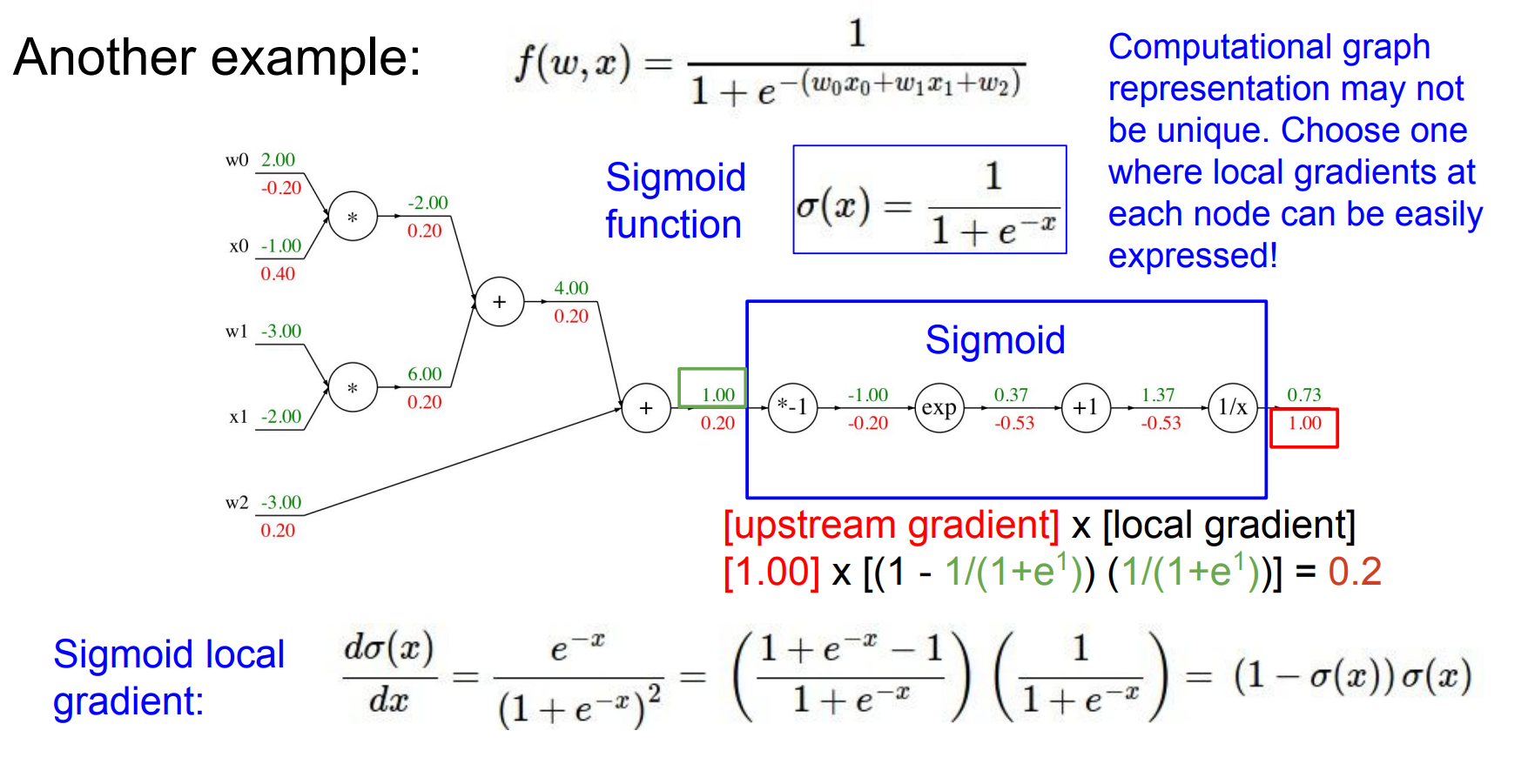
gate
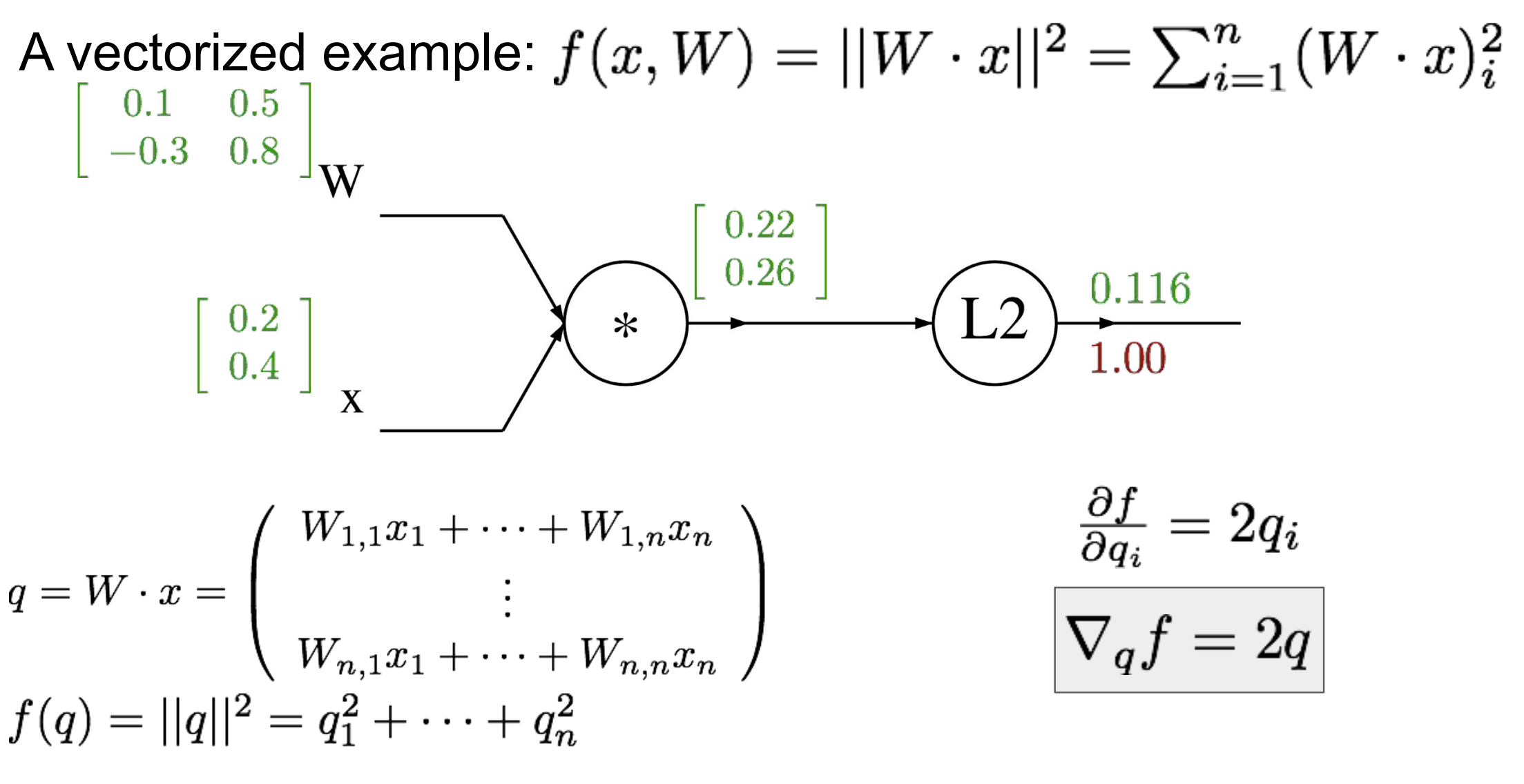
vectorized example
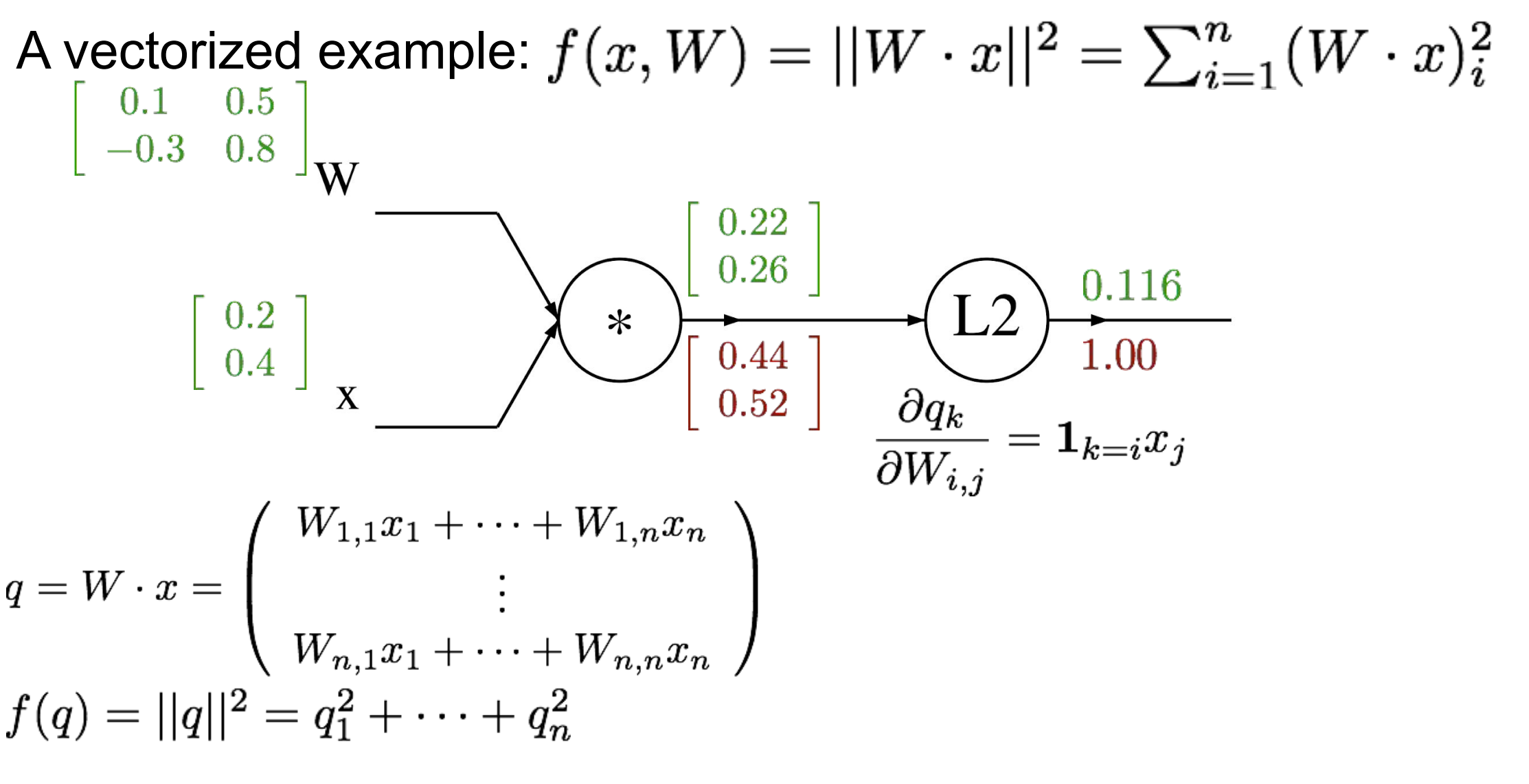
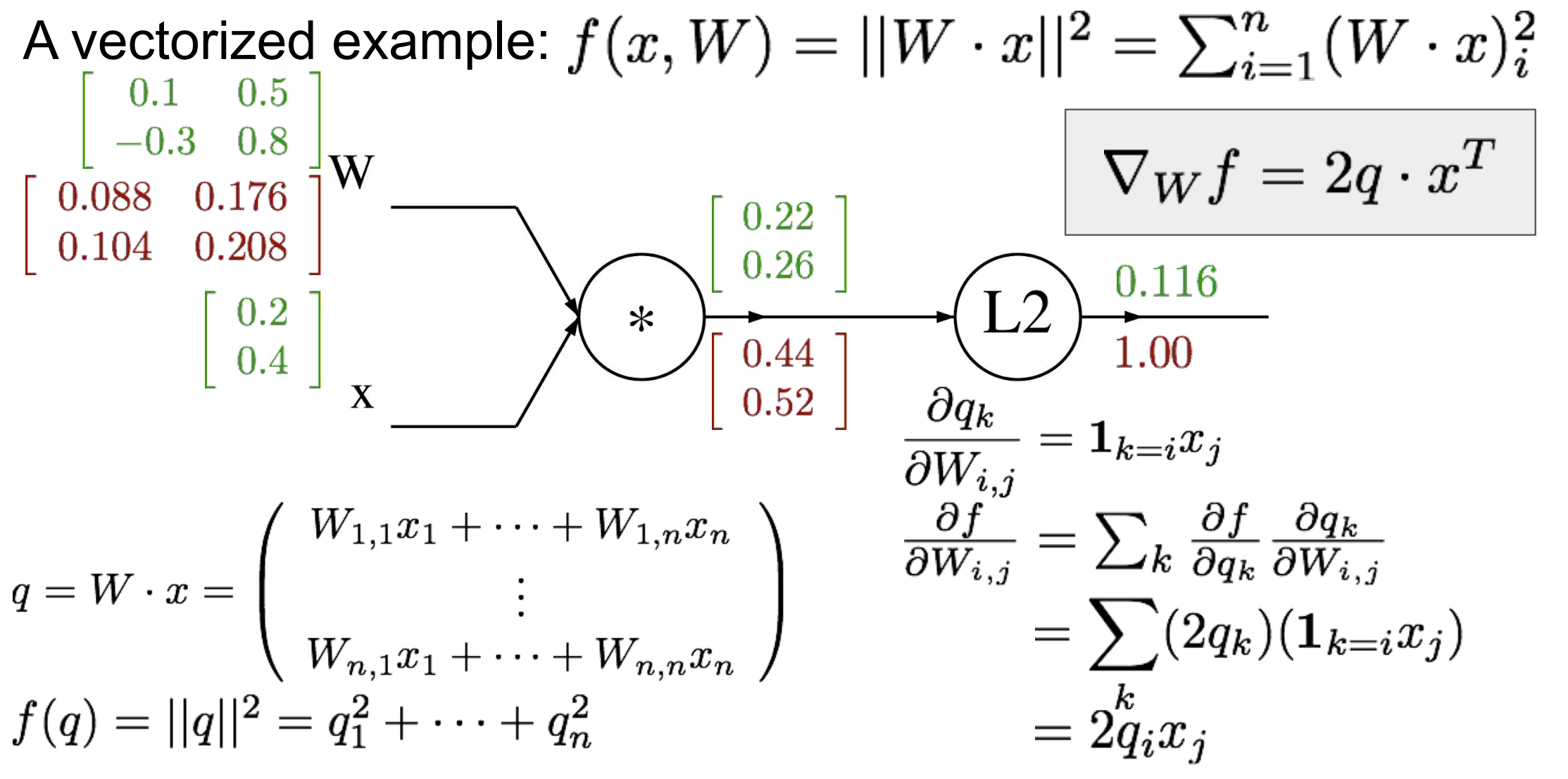
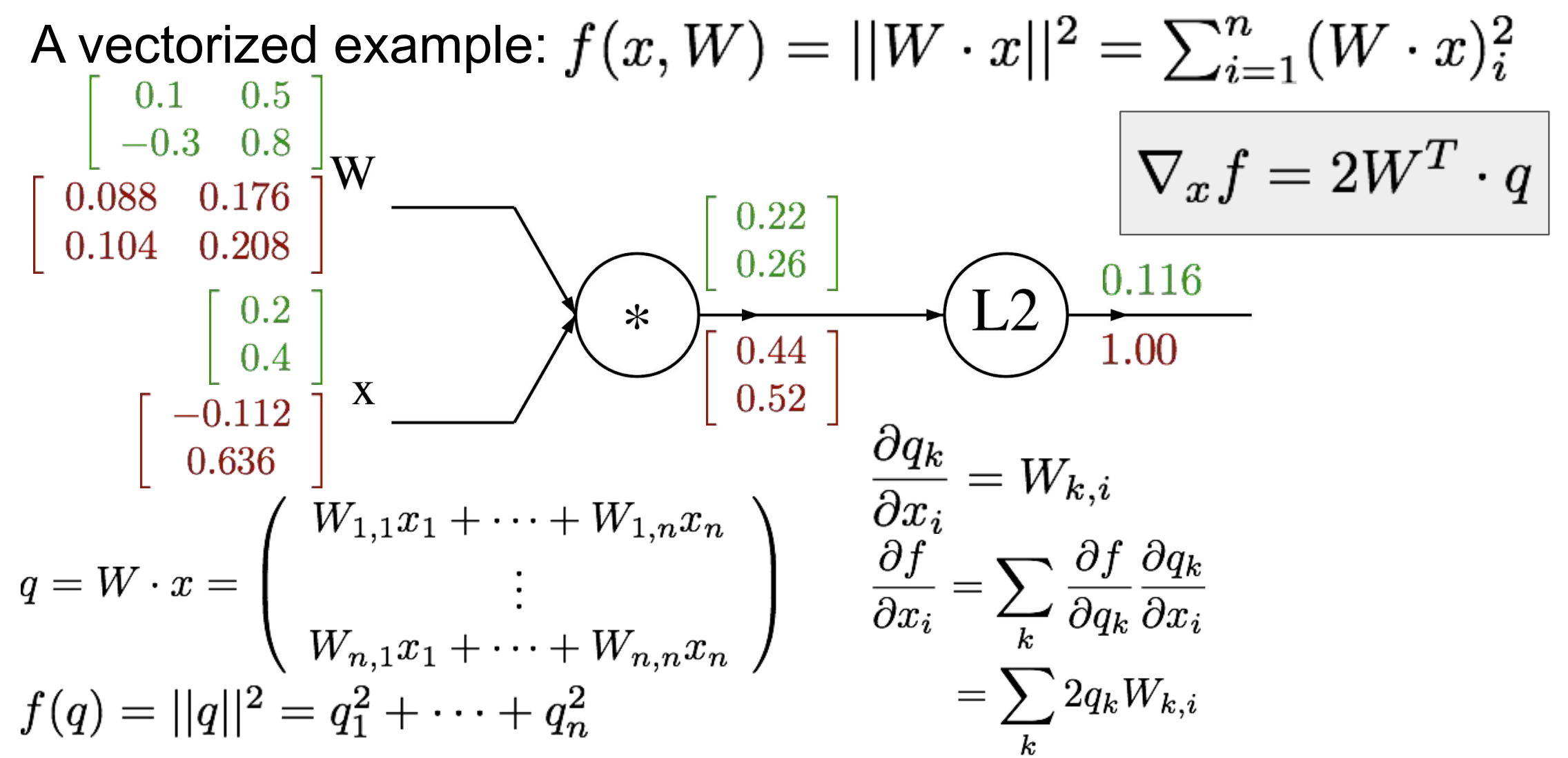
例题