
分类问题

图像分类会遇到的问题
语义鸿沟
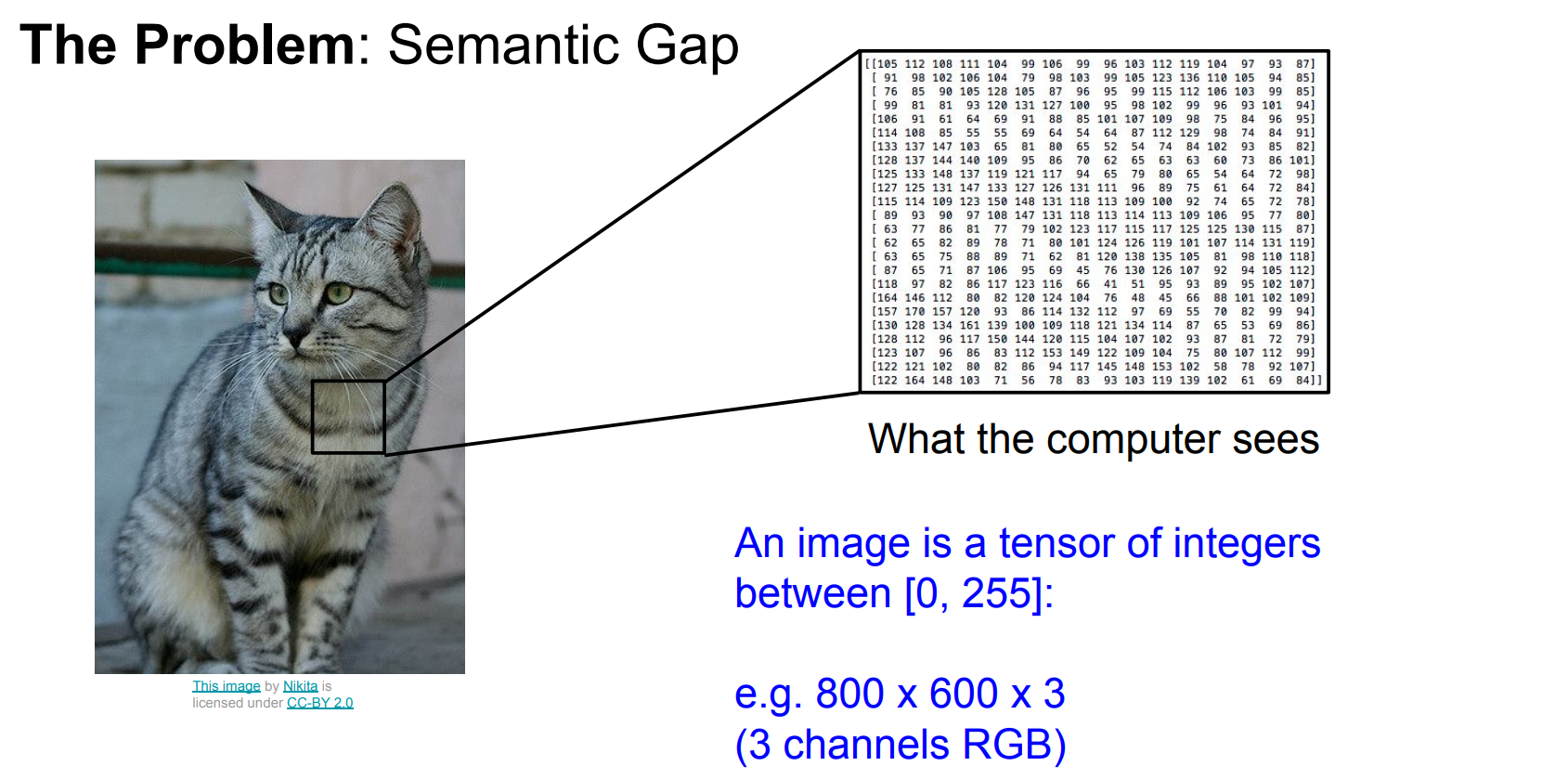
1、低级特征: 低级特征通常是从原始输入数据中提取的,例如图像中的像素值。在计算机视觉中,低级特征可能包括边缘、颜色、纹理等基本信息。这些特征通常在网络的浅层卷积层中提取。
2、高级特征: 高级特征是通过多个卷积层和池化层等深度学习网络的中间层次生成的。这些特征对于更抽象的概念和语义信息更加敏感,如物体、场景、对象关系等。
语义鸿沟的问题在于,尽管高级特征对于理解图像中的语义信息非常重要,但与低级特征相比,它们的表示更加抽象和难以解释。因此,在高级特征和低级特征之间存在一种差距,这使得计算机在理解和解释这些特征之间的关系时面临挑战。
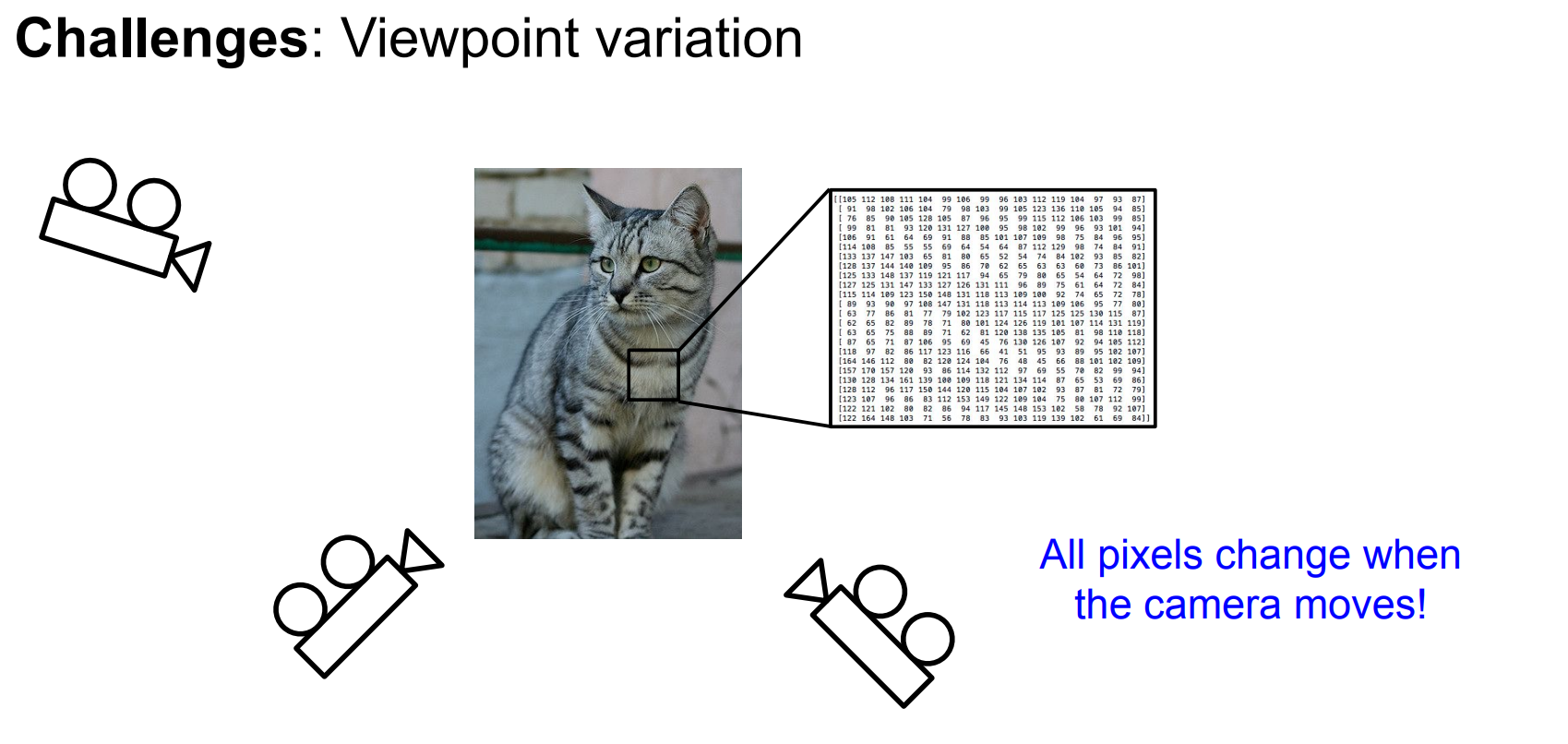
视角变化
光照

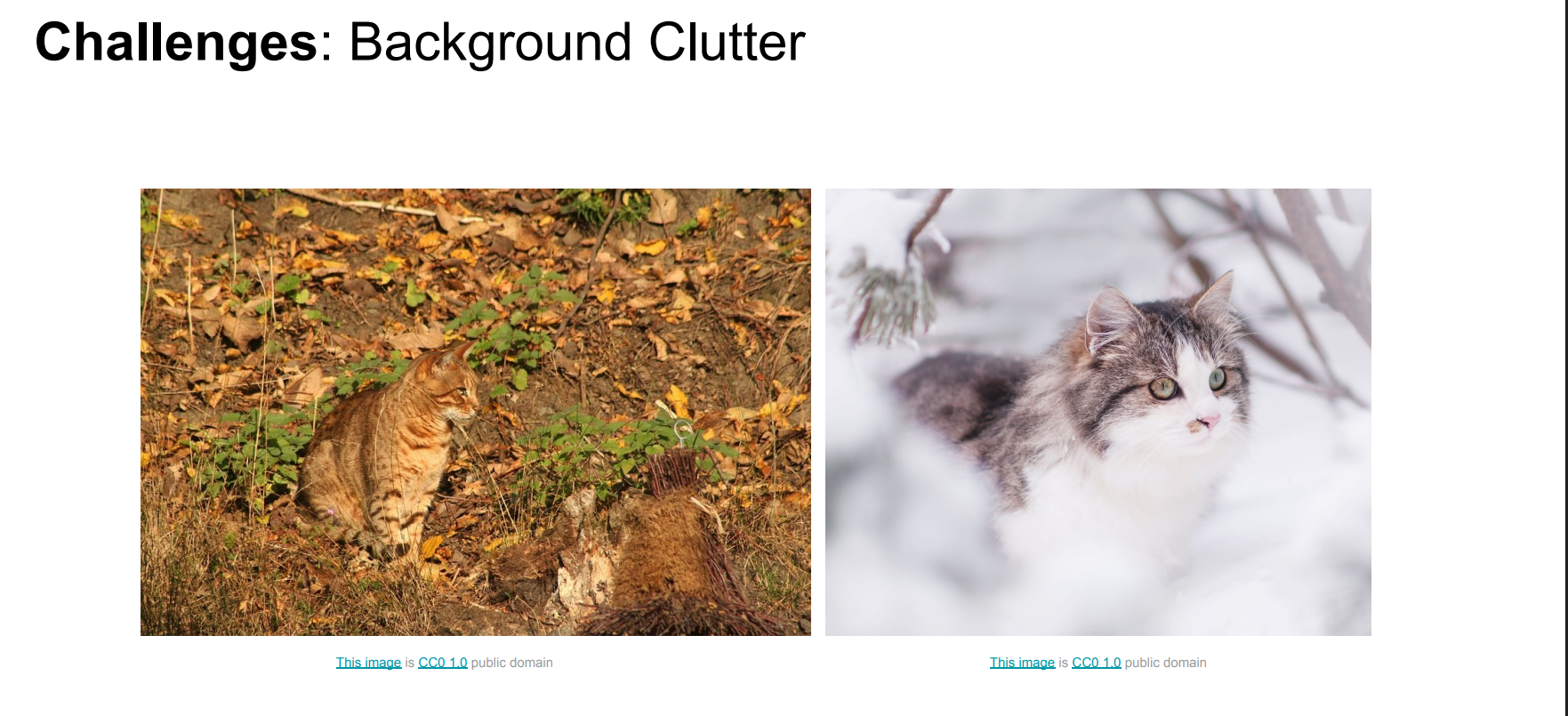
背景杂乱
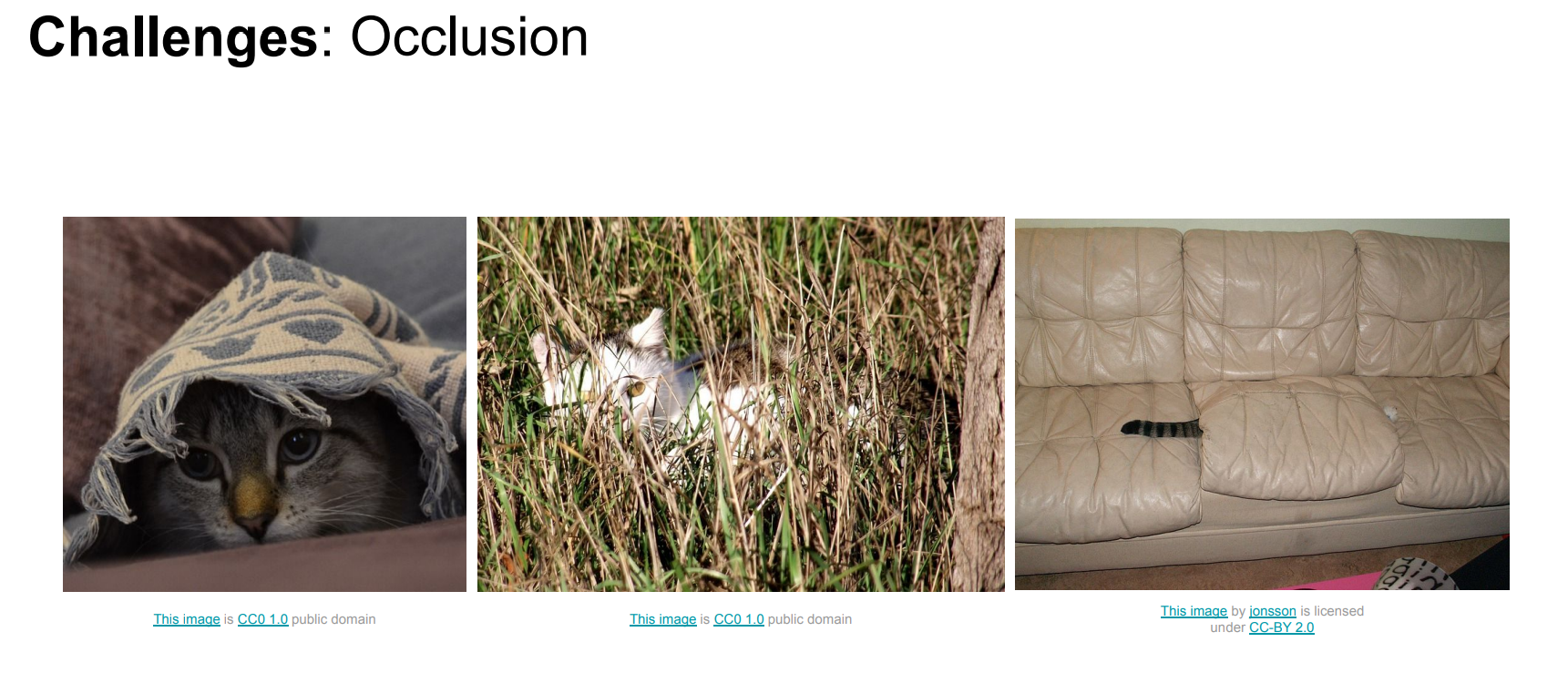
遮挡
形变

类内差异

Nearest Neighbor Classifier
K-NN
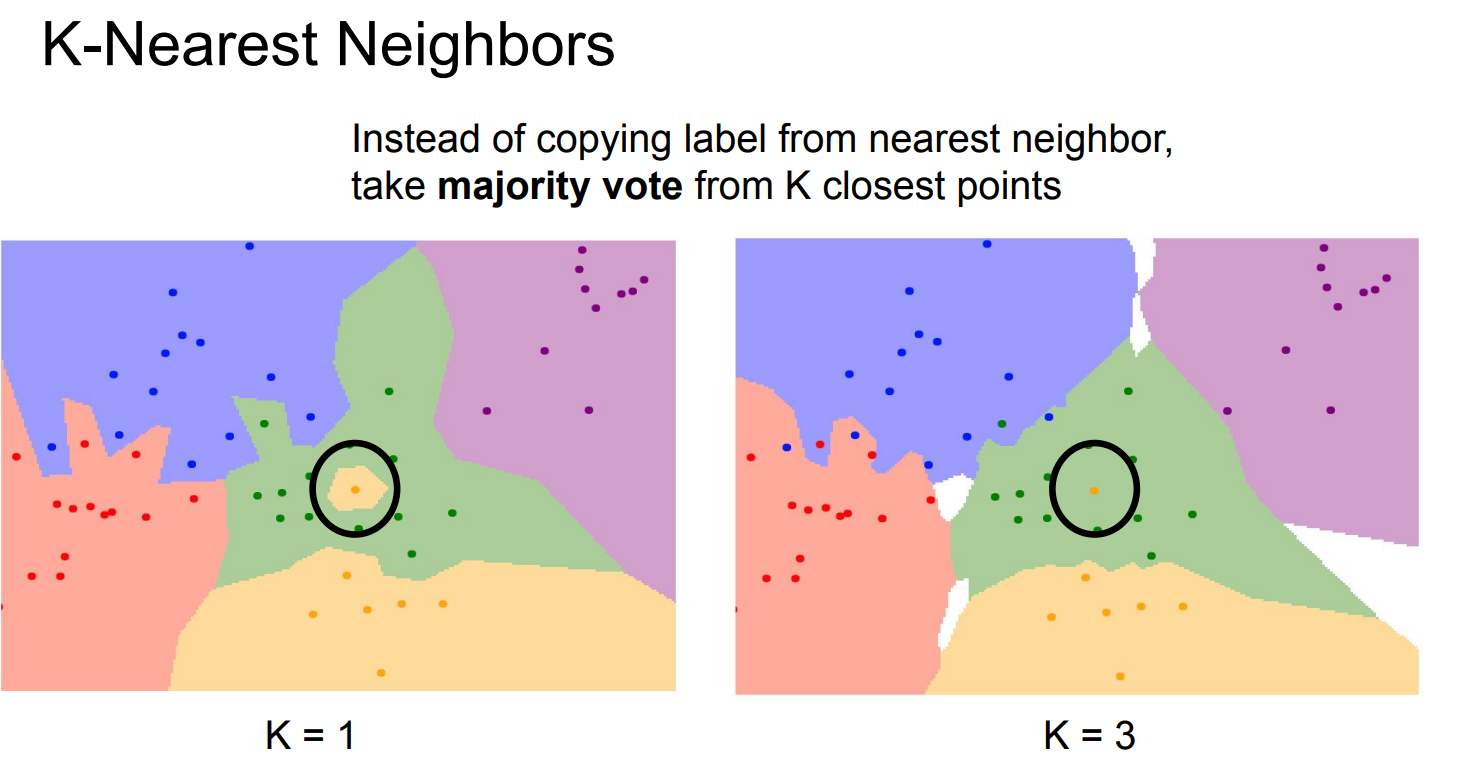
左图 K = 1(1-NN) 的含义是:对黑圈里的测试点,只看离它最近的那一个训练点,这个最近点是黄色的,于是整个小区域都被判成黄色;哪怕周围其实有很多绿色点,只要最近的那一个是黄色,结果就会被“带偏”,所以边界会被拉出很多细碎、尖锐的小岛,看起来非常破碎、对噪声极敏感。
右图 K = 3(3-NN) 则是:对同一个黑圈测试点,看最近的 3 个训练点,虽然其中可能有 1 个是黄色,但如果另外 2 个是绿色,那么绿色 2 票、黄色 1 票,最终判成绿色;因此单个“异常点”不会轻易改变分类结果,整块区域会更平滑、稳定,小噪声点不再产生孤立的分类小块。
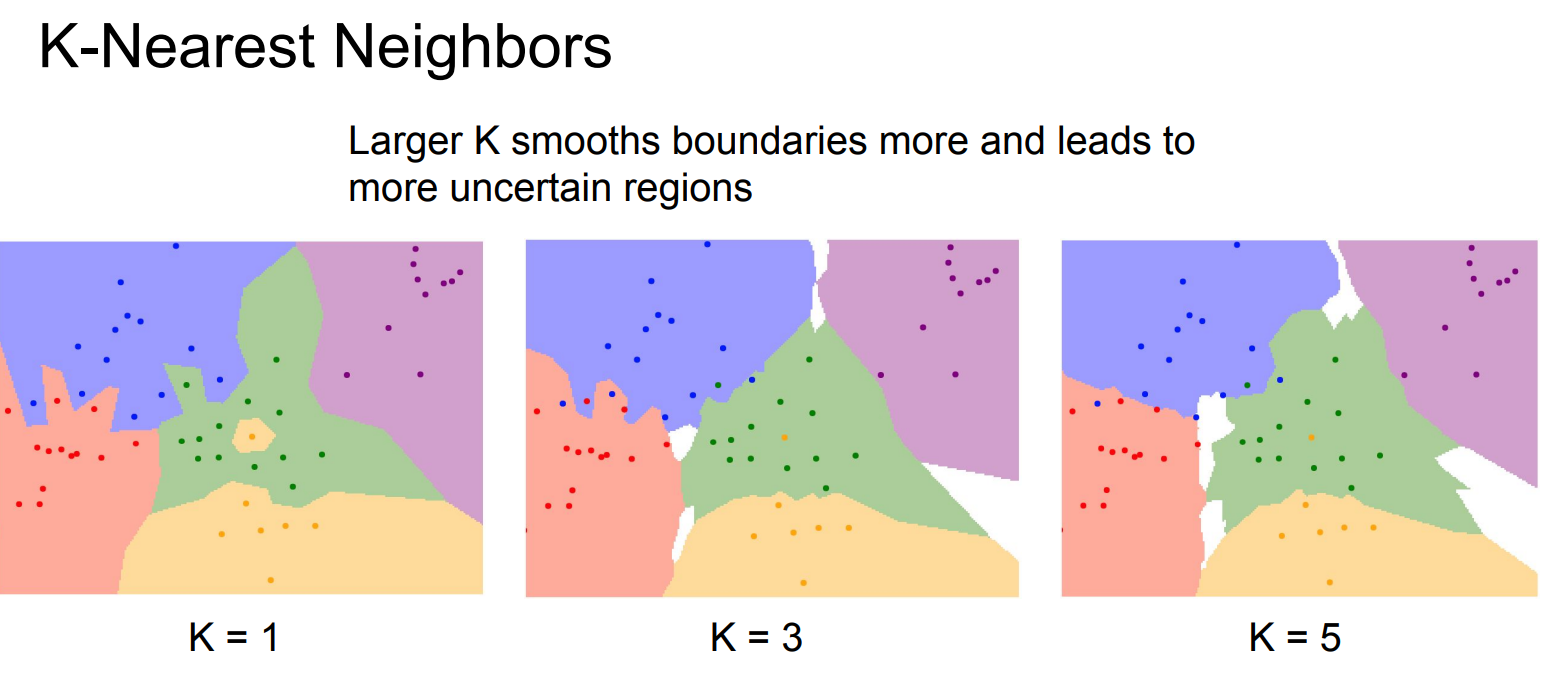
当 K 很大时,产生白色地带:
邻域会同时包含区域颜色越多
投票比例接近
小变化不会立刻改变结果(“平滑”的定义。)
但模型也很难“自信地偏向一边”
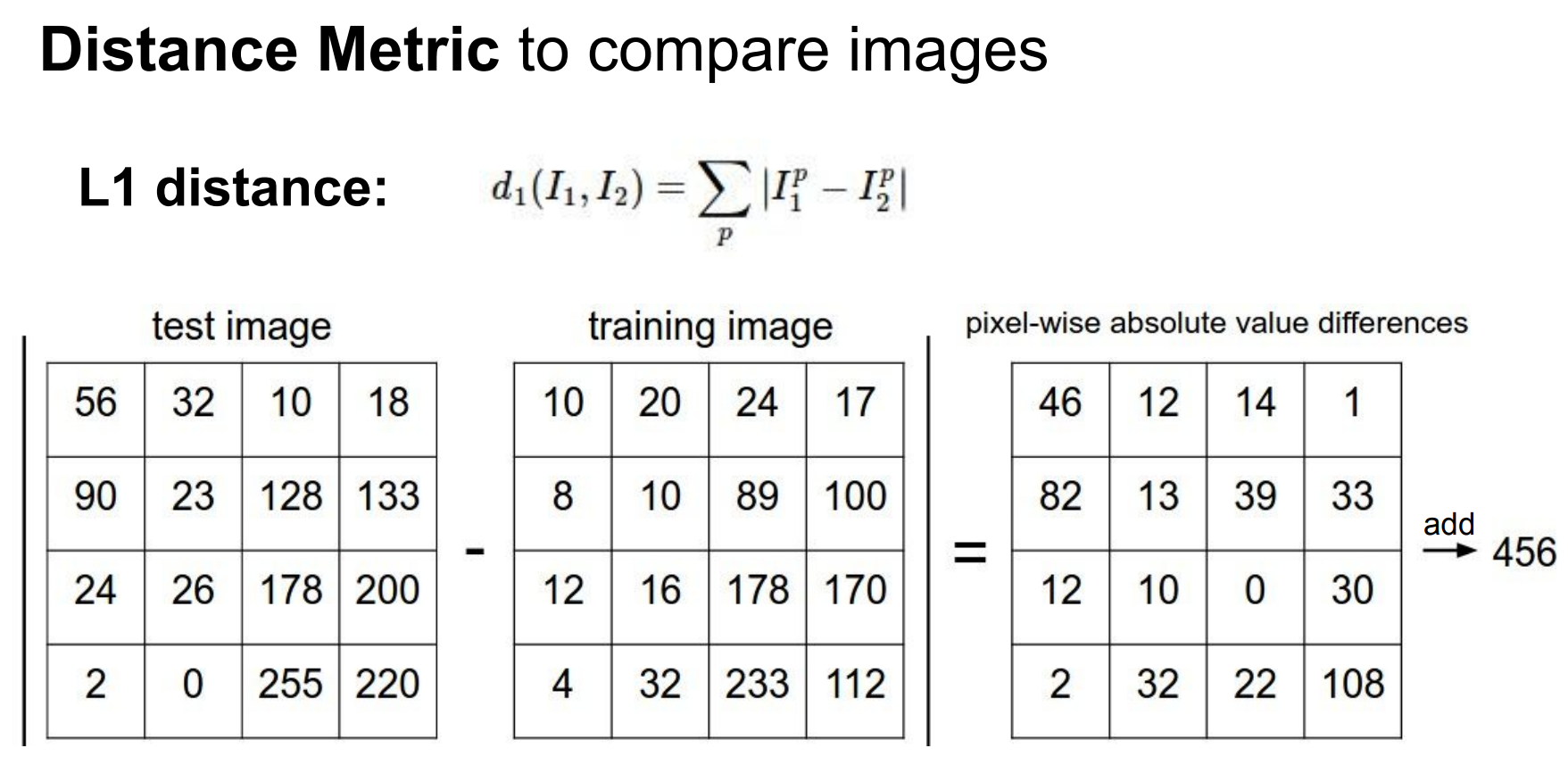
Distance
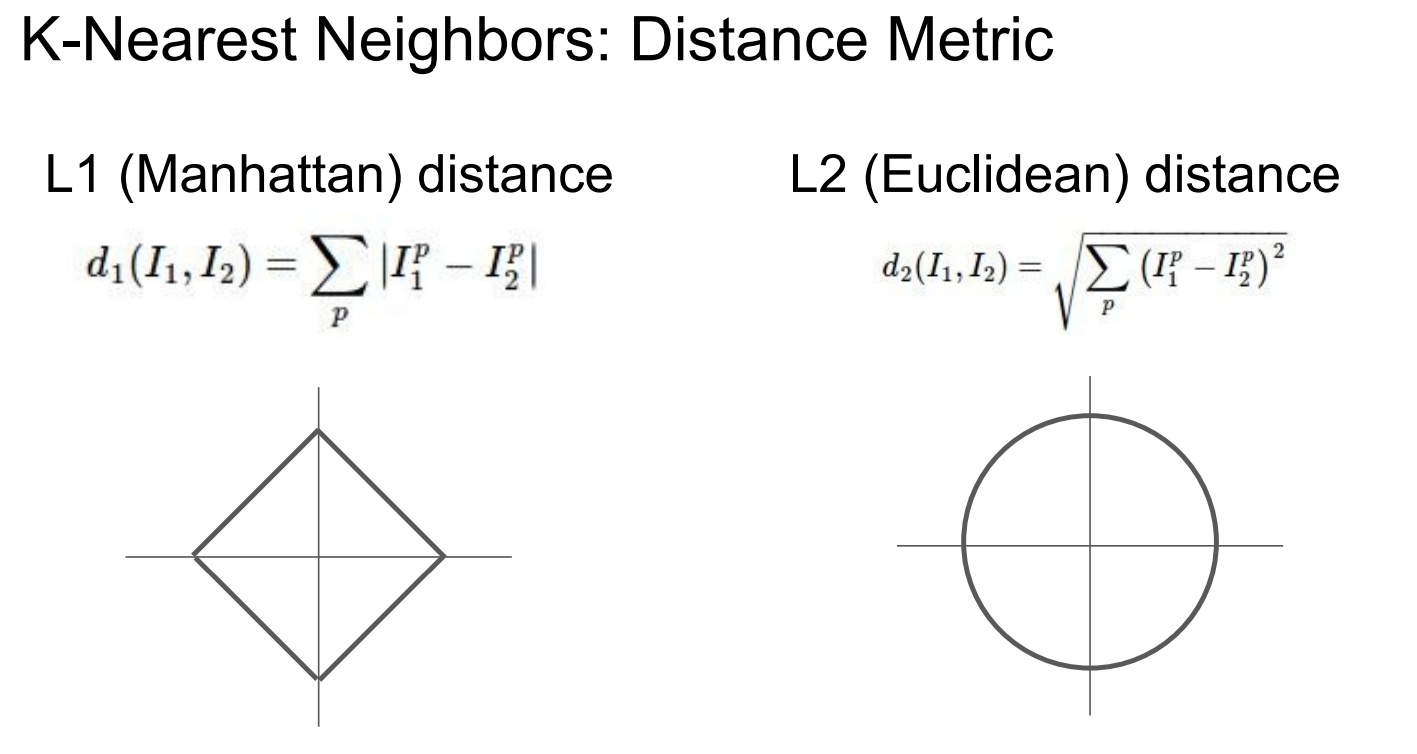
pixel distance

像素级距离对语义变化不敏感,对非语义变化却极其敏感,因此在像素空间中使用 k-NN 进行图像分类是不可行的;必须先学习具有语义不变性的特征表示,再在该特征空间中使用距离度量
参数
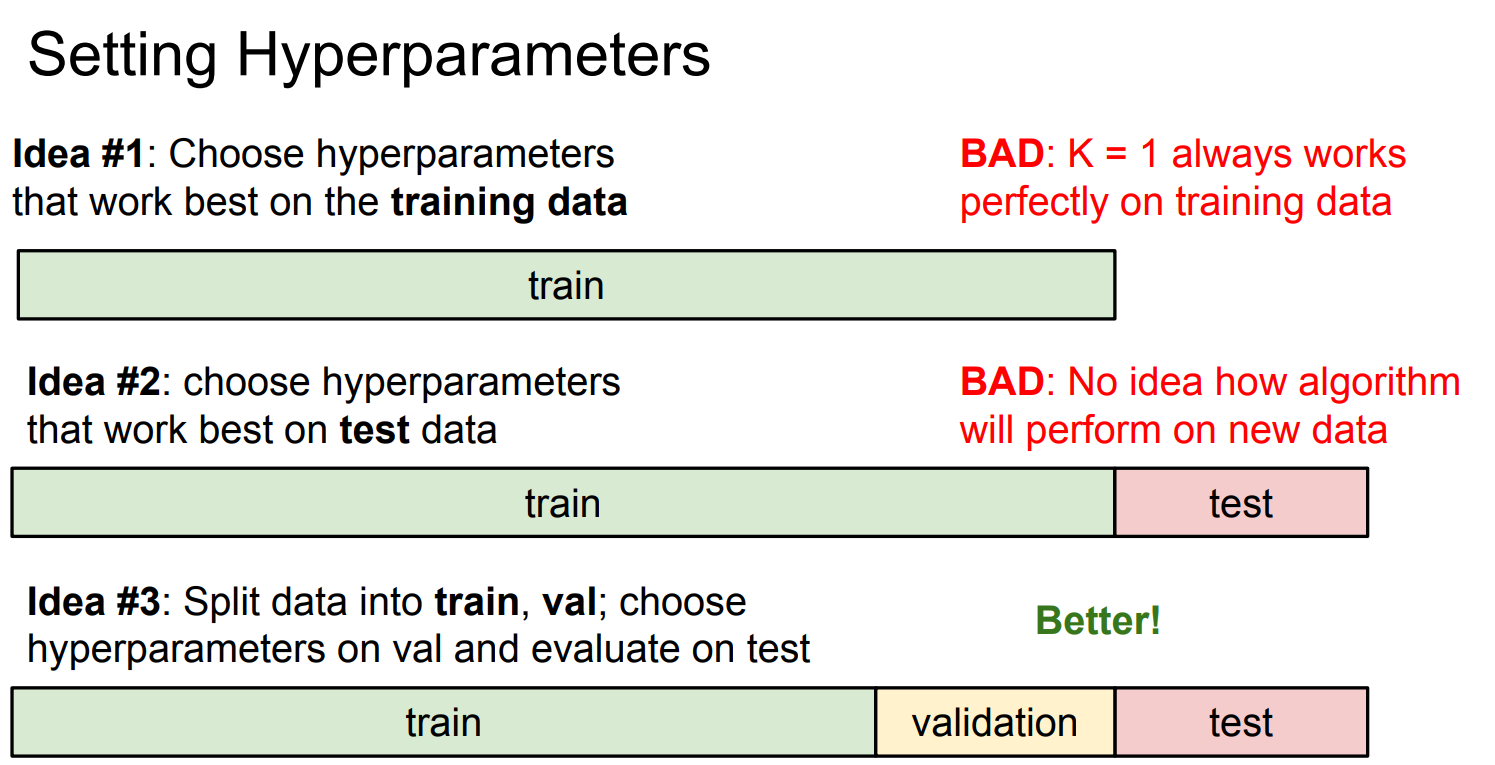
idea1:把训练数据记住了,并不代表能预测新数据,overfiting
idea2:模拟“未来从未见过的数据”,如果你用它来反复试 K、调参数, 那你已经 “偷偷见过未来”,
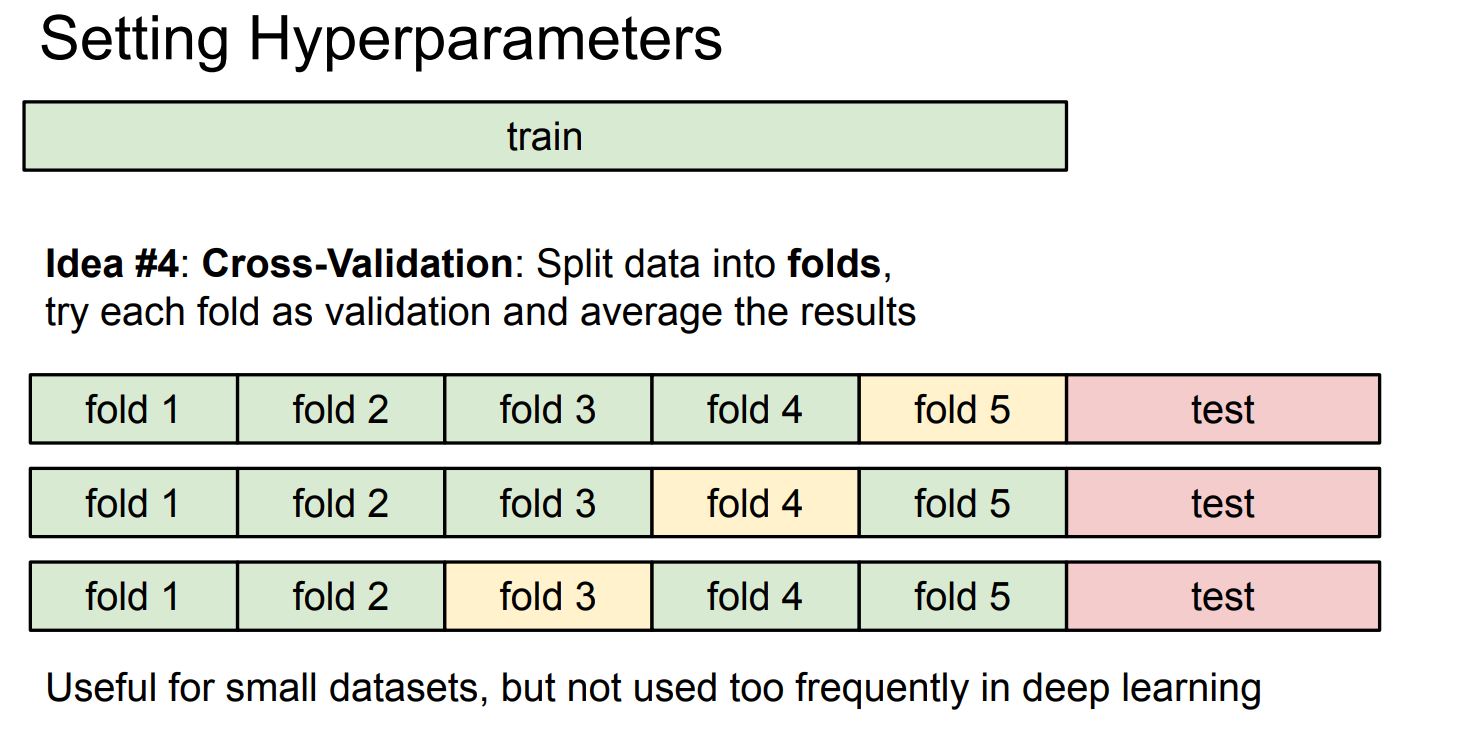
对某个 K 值:
第 1 折:
用 fold 2–5 做近邻库
在 fold 1 上算 accuracy
第 2 折:
用 fold 1,3–5 做近邻库
在 fold 2 上算 accuracy
取 5 次 accuracy 的平均
这就是“同一个 K,被验证了 5 次”。
效果
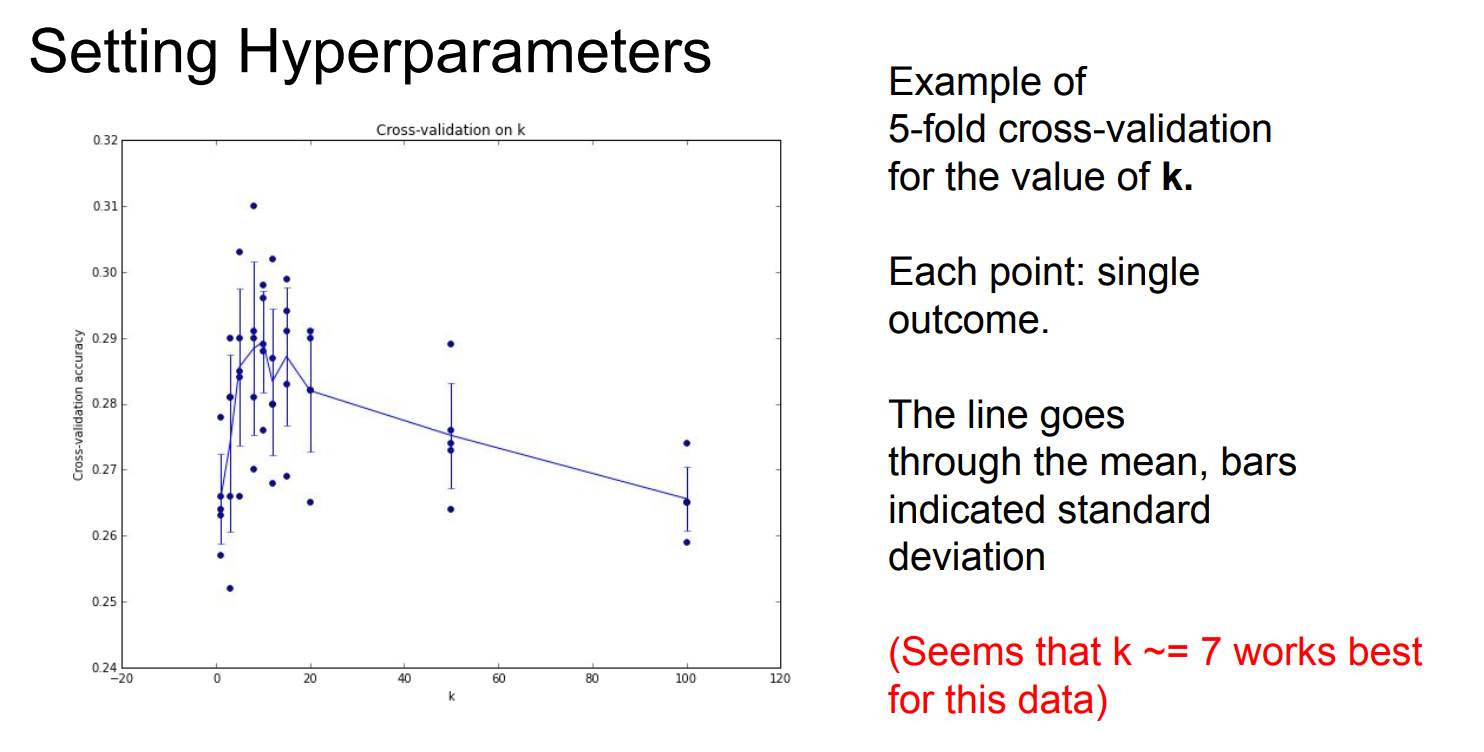
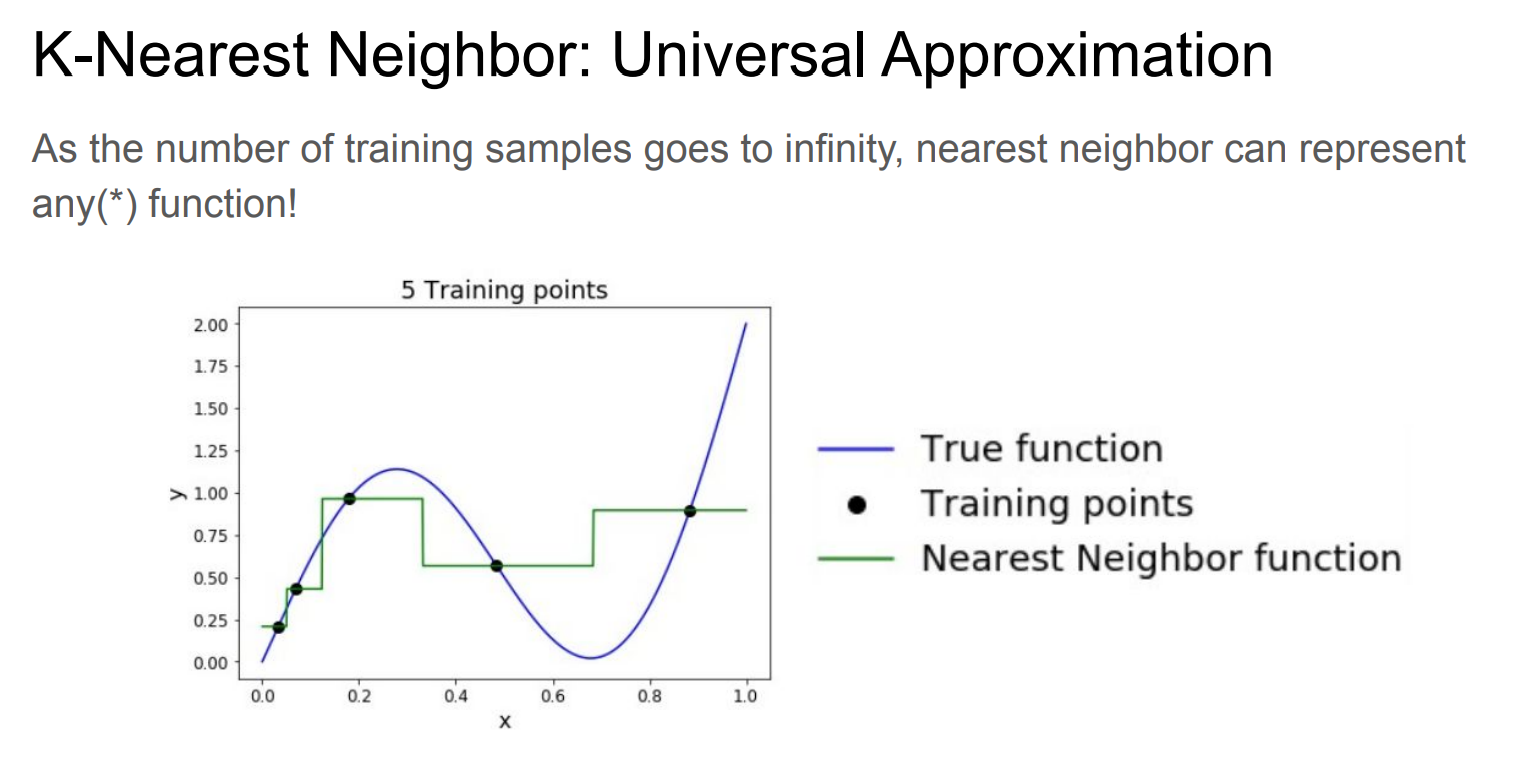
逼近
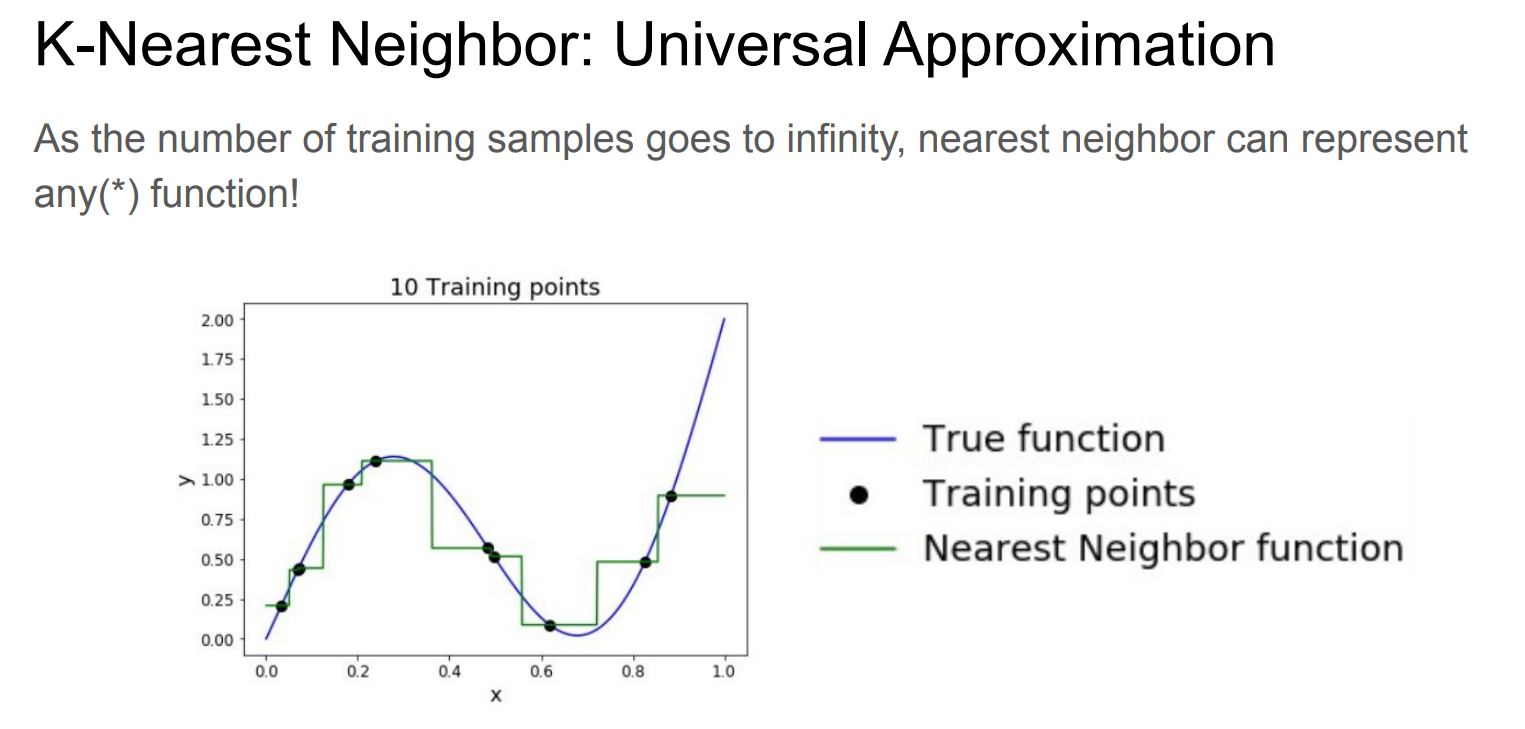
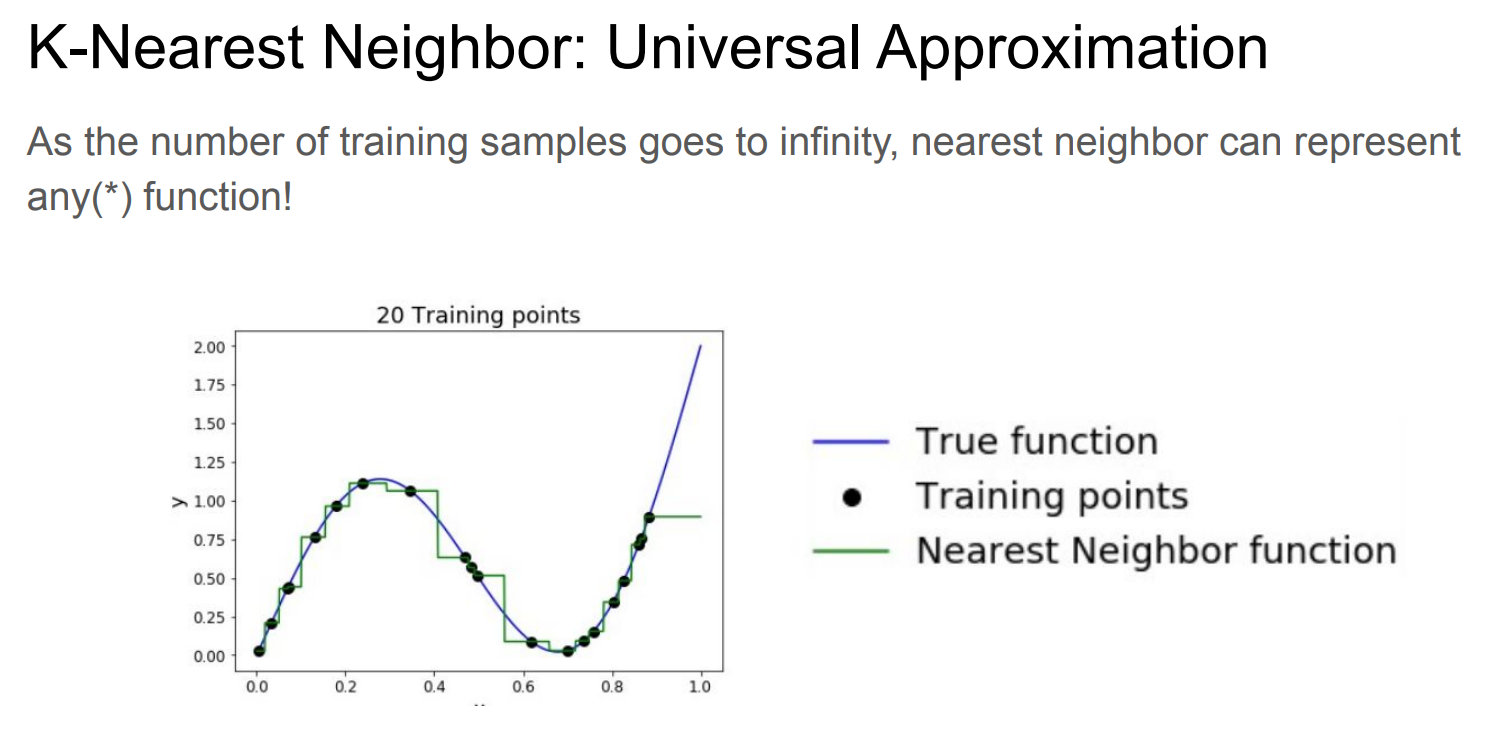
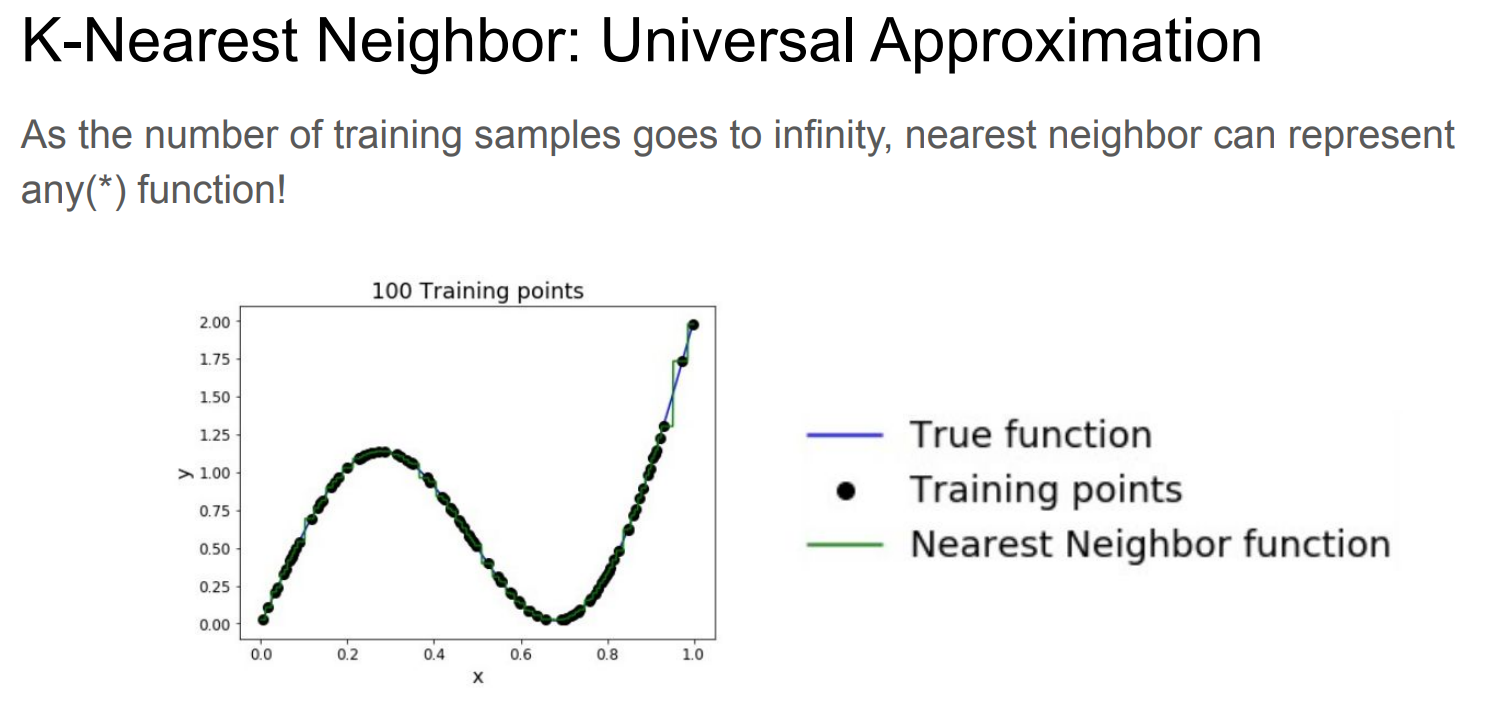
稀疏
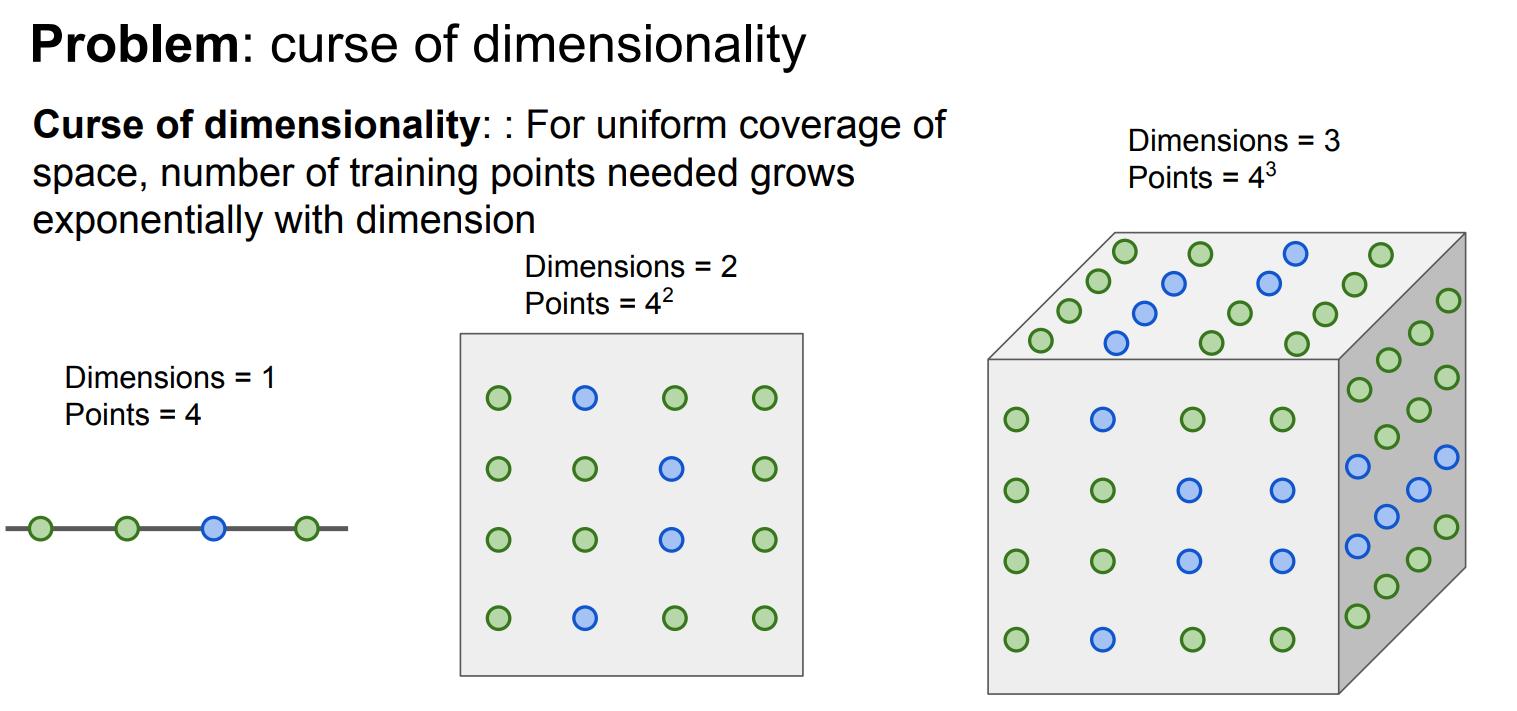
k-NN 的核心假设是:
附近一定有“足够近、足够像”的点
但在高维空间中:
空间体积急剧增大
数据点变得极度稀疏
“最近邻”其实也很远
结果:
k-NN 找到的“邻居”并不相似
距离失去区分度(最近和最远差不多远)

不同角度分析
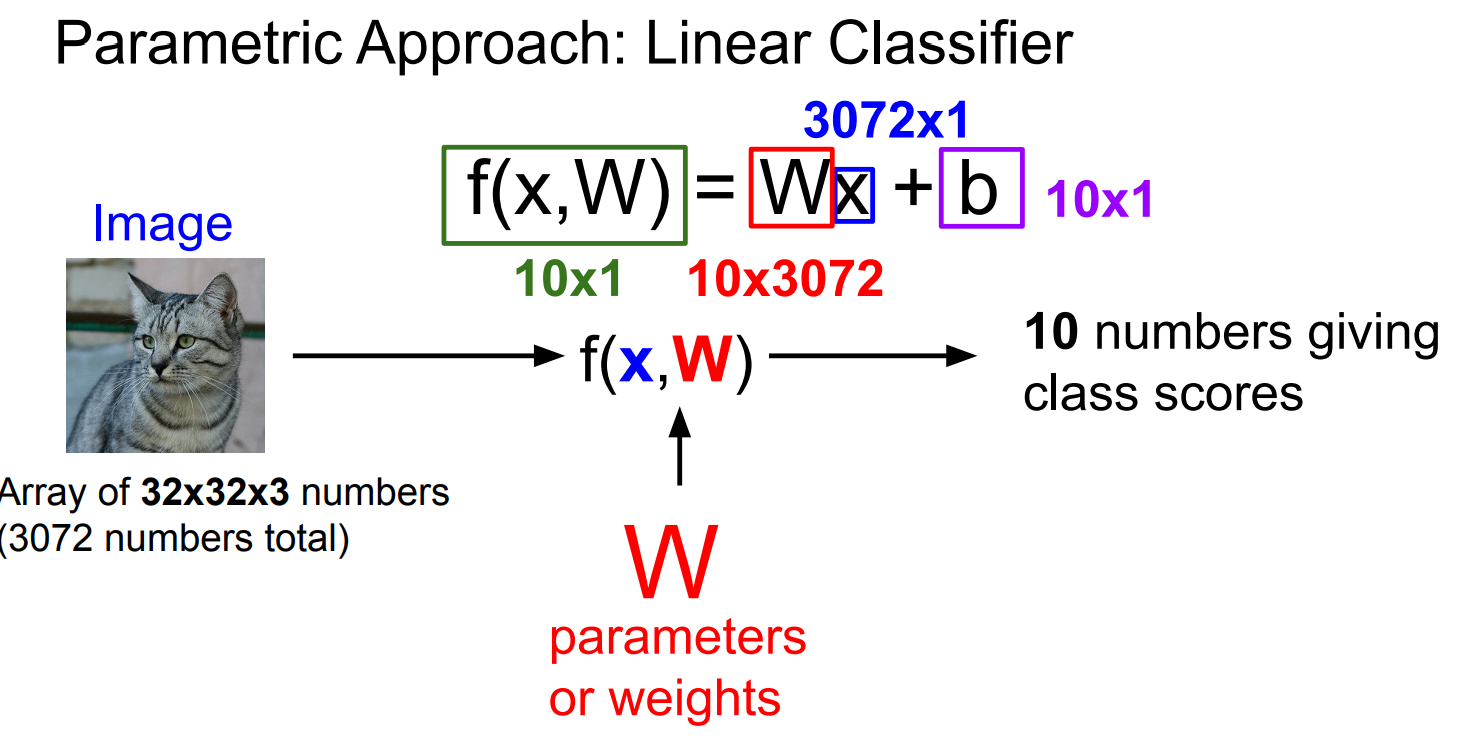
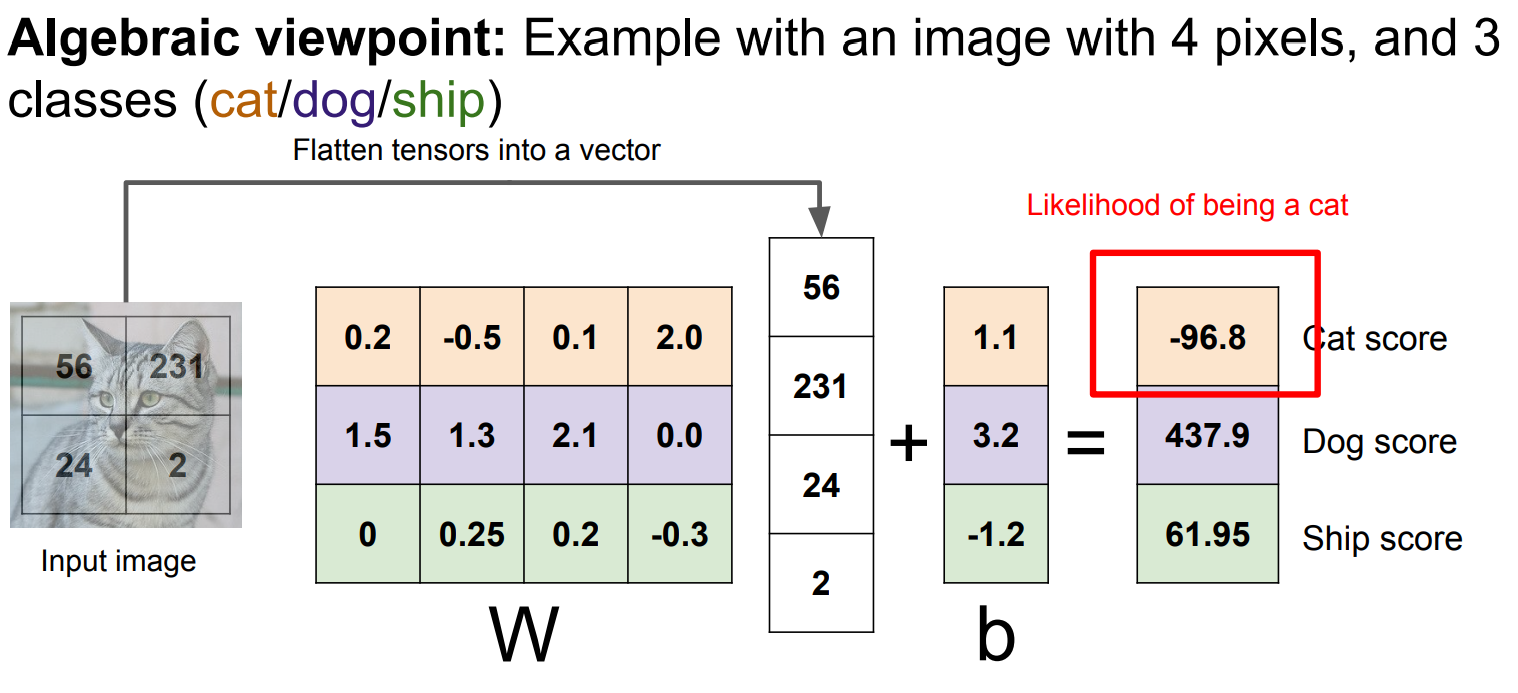
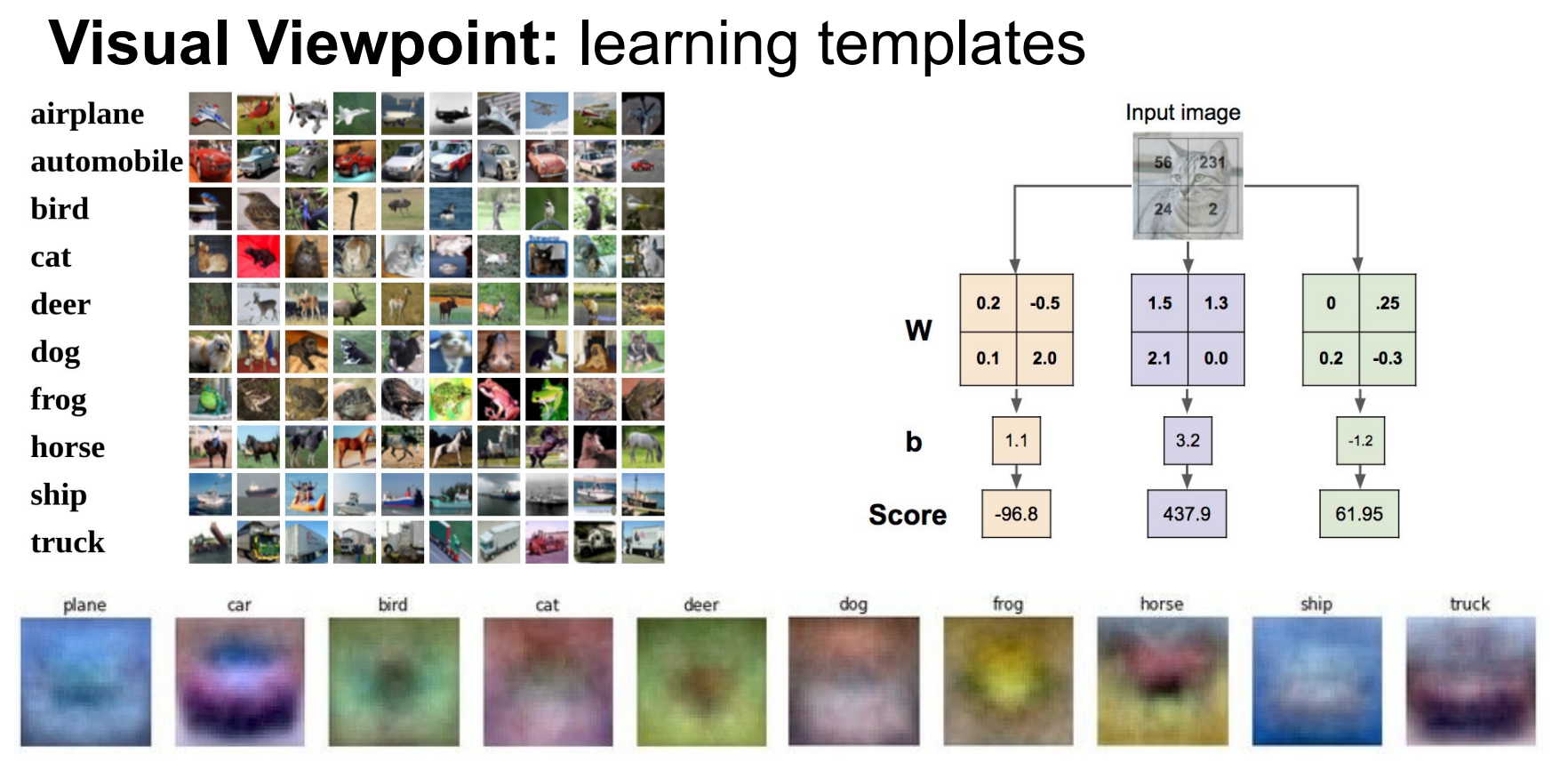
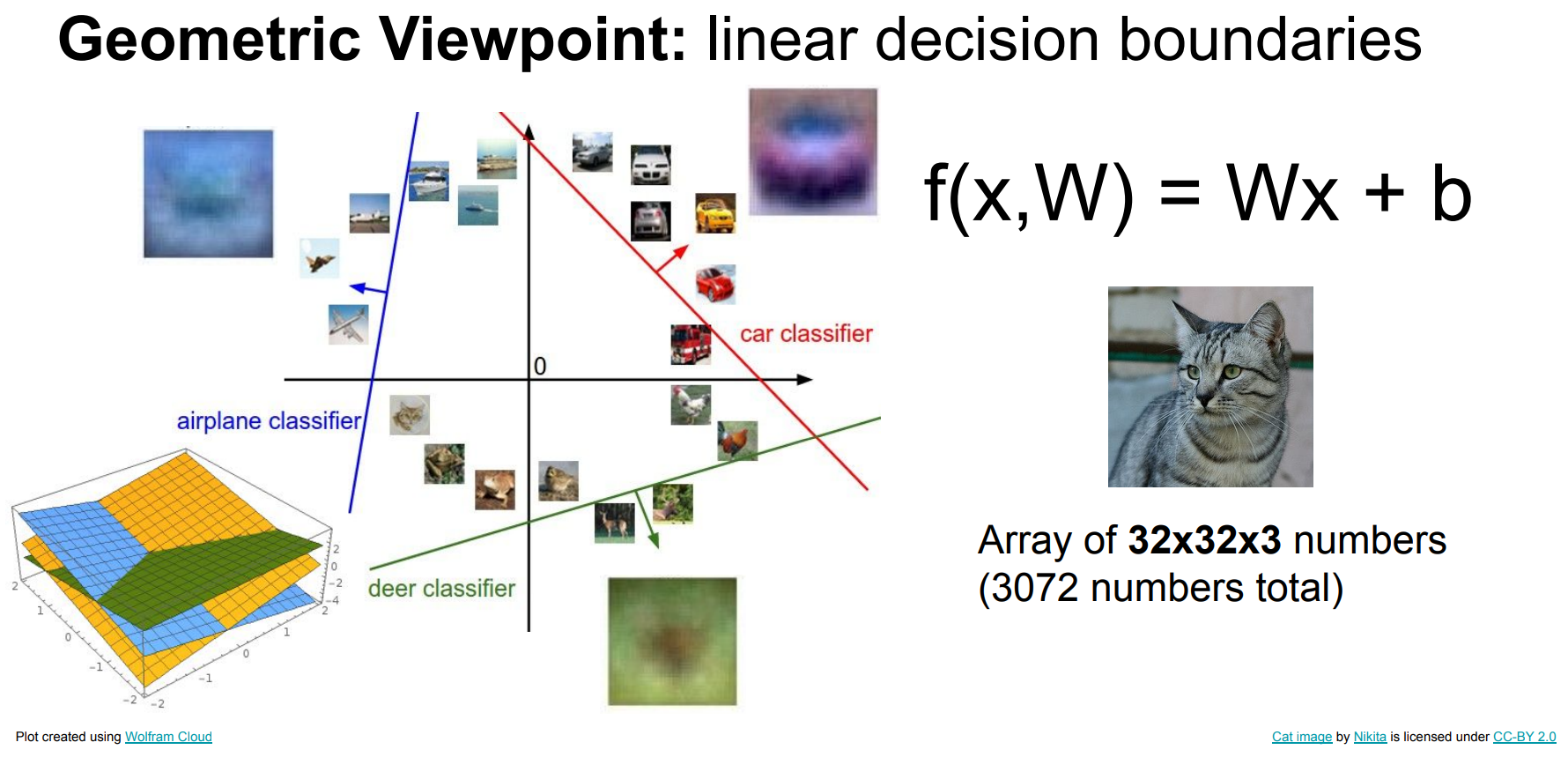
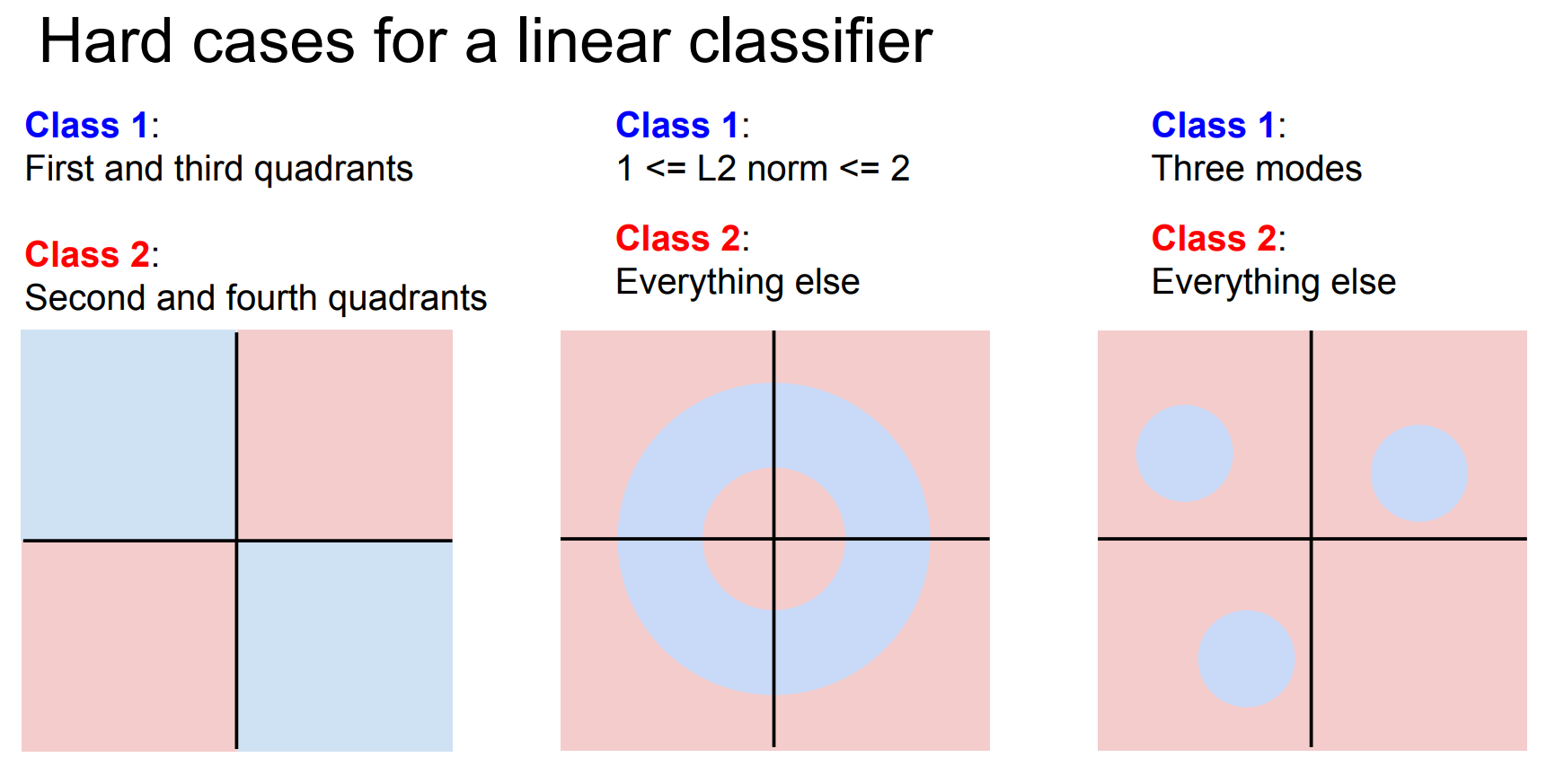
线性分类的难点
Label 到 索引
1 | image_labels = images.get_image_labels() |
索引 得到 图片
1 | paths_of_images_to_display = [] |
Matrix

1 | # fill in A and B so that AB = C, where index i,j in matrix C is the cost of your groceries for week i at store j |